Expert
- Principles of Object Oriented Design
- Architectural Patterns: SOA and EDA
- Patterns of Enterprise Architecture Applications
Core J2EE Patterns (Java developers only)MS Architecture Application Guide (.Net developers only)- Architecture Qualities
- Microservice architecture
- Microkernel Architecture
- SOA
- GoF
- Patterns of Enterprise Architecture Applications:
Principles of Object Oriented Design
- The Open Closed Principle
A module should be open for extension but closed for modification.
We should write our modules so that they can be extended, without requiring them to be modified. In other words, we want to be able to change what the modules do, without changing the source code of the modules.
- The Liskov Substitution Principle
Subclasses should be substitutable for their base classe
Derived classes should be substitutable for their base classes
- The Dependency Inversion Principle
Depend upon Abstractions. Do not depend upon concretions.
Dependency Inversion is the strategy of depending upon interfaces or abstract functions and classes, rather than upon concrete functions and classes
Depending upon Abstractions. The implication of this principle is quite simple. Every dependency in the design should target an interface, or an abstract class. No dependency should target a concrete class.
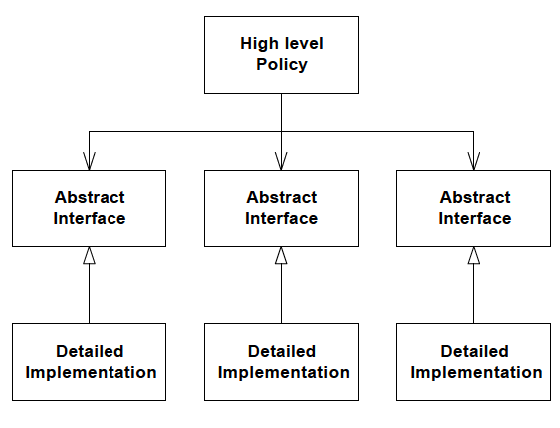
- The Interface Segregation Principle
Many client specific interfaces are better than one general purpose interface
If you have a class that has several clients, rather than loading the class with all the methods that the clients need, create specific interfaces for each client and multiply inherit them into the class.
Principles of Package Architecture
- The Release Reuse Equivalency Principle
The granule of reuse is the granule of release.
A reusable element, be it a component, a class, or a cluster of classes, cannot be reused unless it is managed by a release system of some kind. Users will be unwilling to use the element if they are forced to upgrade every time the author changes it. Thus. even though the author has released a new version of his reusable element, he must be willing to support and maintain older versions while his customers go about the slow business of getting ready to upgrade. Thus, clients will refuse to reuse an element unless the author promises to keep track of version numbers, and maintain old versions for awhile. Therefore, one criterion for grouping classes into packages is reuse. Since packages are the unit of release, they are also the unit of reuse. Therefore architects would do well to group reusable classes together into packages.
- The Common Closure Principle
Classes that change together, belong together
A large development project is subdivided into a large network of interelated packages. The work to manage, test, and release those packages is non-trivial. The more packages that change in any given release, the greater the work to rebuild, test, and deploy the release. Therefore we would like to minimze the number of packages that are changed in any given release cycle of the product.
To achieve this, we group together classes that we think will change together. This requires a certain amount of precience since we must anticipate the kinds of changes that are likely. Still, when we group classes that change together into the same packages, then the package impact from release to release will be minimzed.
- The Common Reuse Principle
Classes that aren’t reused together should not be grouped together.
A dependency upon a package is a dependency upon everything within the package. When a package changes, and its release number is bumped, all clients of that package must verify that they work with the new package -- even if nothing they used within the package actually changed. We frequently experience this when our OS vendor releases a new operating system. We have to upgrade sooner or later, because the vendor will not support the old version forever. So even though nothing of interest to us changed in the new release, we must go through the effort of upgrading and revalidating.
The same can happen with packages if classes that are not used together are grouped together. Changes to a class that I don’t care about will still force a new release of the package, and still cause me to go through the effort of upgrading and revalidating.
Architectural Patterns: SOA and EDA
SOA
Service-Oriented Architecture (SOA) is a style of software design where services are provided to the other components by application components, through a communication protocol over a network. Its principles are independent of vendors and other technologies. In service oriented architecture, a number of services communicate with each other, in one of two ways: through passing data or through two or more services coordinating an activity. This is just one definition of Service-Oriented Architecture.
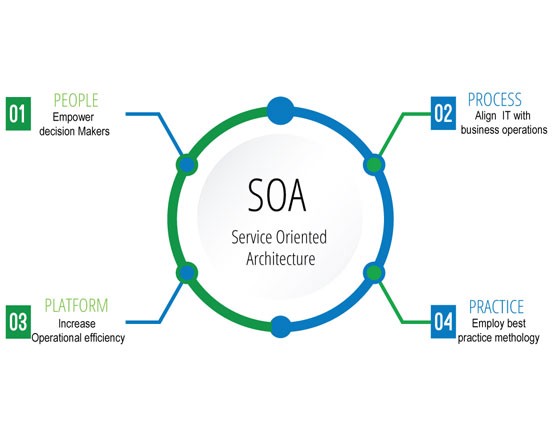
Characteristics Of Service-Oriented Architecture
While the defining concepts of Service-Oriented Architecture vary from company to company, there are six key tenets that overarch the broad concept of Service-Oriented Architecture. These core values include:
- Business value
- Strategic goals
- Intrinsic inter-operability
- Shared services
- Flexibility
- Evolutionary refinement
Each of these core values can be seen on a continuum from older format distributed computing to Service-Oriented Architecture to cloud computing (something that is often seen as an offshoot of Service-Oriented Architecture).
Service-Oriented Architecture Patterns
There are three roles in each of the Service-Oriented Architecture building blocks: service provider; service broker, service registry, service repository; and service requester/consumer.
The service provider works in conjunction with the service registry, debating the whys and hows of the services being offered, such as security, availability, what to charge, and more. This role also determines the service category and if there need to be any trading agreements.
The service broker makes information regarding the service available to those requesting it. The scope of the broker is determined by whoever implements it.
The service requester locates entries in the broker registry and then binds them to the service provider. They may or may not be able to access multiple services; that depends on the capability of the service requester.
Implementing Service-Oriented Architecture
When it comes to implementing service-oriented architecture (SOA), there is a wide range of technologies that can be used, depending on what your end goal is and what you’re trying to accomplish.
Typically, Service-Oriented Architecture is implemented with web services, which makes the “functional building blocks accessible over standard internet protocols.”
An example of a web service standard is SOAP, which stands for Simple Object Access Protocol. In a nutshell, SOAP “is a messaging protocol specification for exchanging structured information in the implementation of web services in computer networks. Although SOAP wasn’t well-received at first, since 2003 it has gained more popularity and is becoming more widely used and accepted. Other options for implementing Service-Oriented Architecture include Jini, COBRA, or REST.
It’s important to note that architectures can “operate independently of specific technologies,” which means they can be implemented in a variety of ways, including messaging, such as ActiveMQ; Apache Thrift; and SORCER.
Why Service-Oriented Architecture Is Important
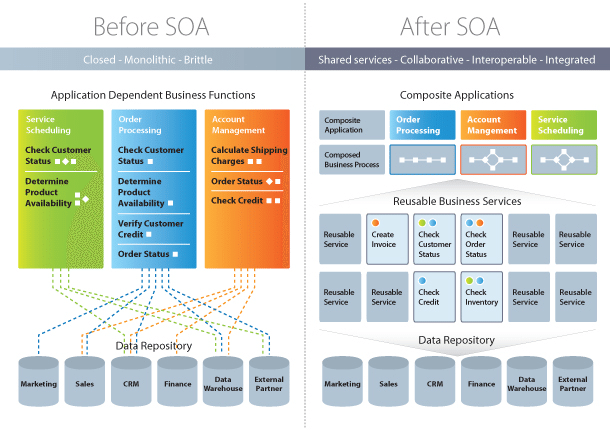
There are many benefits to service-oriented architecture, especially in a web service based business. We’ll outline a few of those benefits here, in brief:
Use Service-Oriented Architecture to create reusable code: Not only does this cut down on time spent on the development process, but there’s no reason to reinvent the coding wheel every time you need to create a new service or process. Service-Oriented Architecture also allows for using multiple coding languages because everything runs through a central interface.
Use Service-Oriented Architecture to promote interaction: With Service-Oriented Architecture, a standard form of communication is put in place, allowing the various systems and platforms to function independent of each other. With this interaction, Service-Oriented Architecture is also able to work around firewalls, allowing “companies to share services that are vital to operations.”
Use Service-Oriented Architecture for scalability: It’s important to be able to scale a business to meet the needs of the client, however certain dependencies can get in the way of that scalability. Using Service-Oriented Architecture cuts back on the client-service interaction, which allows for greater scalability.
Use Service-Oriented Architecture to reduce costs: With Service-Oriented Architecture, it’s possible to reduce costs while still “maintaining a desired level of output.” Using Service-Oriented Architecture allows businesses to limit the amount of analysis required when developing custom solutions.
Differences Between Service-Oriented Architecture and Microservices
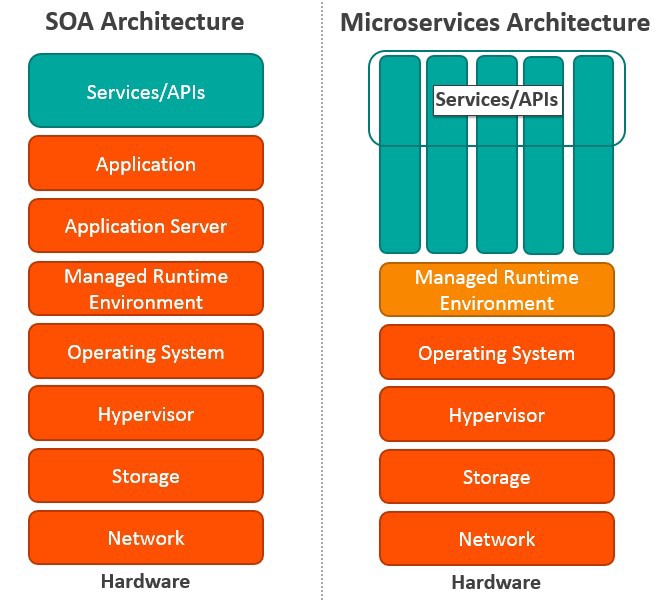
Microservices, also known as Microservice Architecture, is an “architectural style that structures an application as a collection of small autonomous services, modeled around a business domain.”
While microservices and Service-Oriented Architecture are similar in some ways, the key differences come in their functionality. Services is, obviously, the main component of both. There are four basic types of services:
Functional service: these define core business operations
Enterprise service: these implement the functionality defined by the functional services
Application service: these are confined to specific application content
Infrastructure service: implements non-functional tasks such as authentication, auditing, security, and logging
As you can see, each of these services builds on the one before it, creating a system that is not only easy to use, but provides you with a variety of ways to manage your business. As with any functionality, it’s a matter of figuring out what works best for you and your business.
| SOA | MSA |
|---|---|
| Built on the idea of a “share-as-much-as-possible” architecture approach | Built on the idea of “share-as-little-as-possible” architecture approach |
| More importance on business functionality reuse | More importance on the concept of “bounded context” |
| Common governance and standards | Relaxed governance, with more focus on people collaboration and freedom of choice |
| Uses enterprise service bus (ESB) for communication | Uses less elaborate and simple messaging system |
| S | pports multiple message protocols |
| Common platform for all services deployed to it | Application Servers not really used. Platforms such as Node.JS could be used |
| Multi-threaded with more overheads to handle I/O | Single-threaded usually with use of Event Loop features for non-locking I/O handling |
| Use of containers (Dockers, Linux Containers) less popular | Containers work very well in MSA |
| Maximizes application service reusability | More focused on decoupling |
| Uses traditional relational databases more often | Uses modern, non-relational databases |
| A systematic change requires modifying the monolith | A systematic change is to create a new service |
| DevOps / Continuous Delivery is becoming popular, but not yet mainstream | Strong focus on DevOps / Continuous Delivery |
Let’s Explore the Differences in More Detail
Coordination: In SOA, you need to coordinate with multiple groups to create business requests. But there is little or no coordination among services in MSA. If coordination is needed among service owners, it is done through small application development teams, and services can be quickly developed, tested, and deployed.
Service granularity: The prefix “micro” in Microservices refers to the granularity of the internal components. Service components within MSA are generally single purpose services that do one thing really well. Services usually include much more business functionality in SOA, and they are often implemented as complete subsystems.
Component sharing: SOA enhances component sharing, whereas MSA tries to minimize on sharing through “bounded context.” A bounded context refers to the coupling of a component and its data as a single unit with minimal dependencies. As SOA relies on multiple services to fulfill a business request, systems built on SOA are likely to be slower than MSA.
Middleware vs API layer: The messaging middleware in SOA offers a host of additional capabilities not found in MSA, including mediation and routing, message enhancement, message and protocol transformation. MSA has an API layer between services and service consumers.
Remote services: SOA architectures rely on messaging (AMQP, MSMQ) and SOAP as primary remote access protocols. Most MSAs rely on two protocols – REST and simple messaging (JMS, MSMQ), and the protocol found in MSA is usually homogeneous.
Heterogeneous interoperability: SOA promotes the propagation of multiple heterogeneous protocols through its messaging middleware component. MSA attempts to simplify the architecture pattern by reducing the number of choices for integration. If you would like to integrate several systems using different protocols in heterogeneous environment, you need to consider SOA. If all your services could be exposed and accessed through the same remote access protocol, then MSA is a better option.
Contract decoupling: Contract decoupling is the holy grail of abstraction. It offers the greatest degree of decoupling between services and consumers. It is one of the fundamental capabilities offered within SOA. But MSA doesn’t support contract decoupling.
Event-Driven Architecture
In event-driven architecture, when a service performs some piece of work that other services might be interested in, that service produces an event—a record of the performed action. Other services consume those events so that they can perform any of their own tasks needed as a result of the event. Unlike with REST, services that create requests do not need to know the details of the services consuming the requests.
Here’s a simple example: When an order is placed on an ecommerce site, a single “order placed” event is produced and then consumed by several microservices:
- the order service which could write an order record to the database
- the customer service which could create the customer record, and
- the payment service which could process the payment
Events can be published in a variety of ways. For example, they can be published to a queue that guarantees delivery of the event to the appropriate consumers, or they can be published to a pub/sub model stream that publishes the event and allows access to all interested parties. In either case, the producer publishes the event, and the 88 receives that event, reacting accordingly. Note that in some cases, these two actors can also be called the publisher (the producer) and the subscriber (the consumer).
Why Use Event-Driven Architecture
An event-driven architecture offers several advantages over REST, which include:
Asynchronous – event-based architectures are asynchronous without blocking. This allows resources to move freely to the next task once their unit of work is complete, without worrying about what happened before or will happen next. They also allow events to be queued or buffered which prevents consumers from putting back pressure on producers or blocking them.
Loose Coupling – services don’t need (and shouldn’t have) knowledge of, or dependencies on other services. When using events, services operate independently, without knowledge of other services, including their implementation details and transport protocol. Services under an event model can be updated, tested, and deployed independently and more easily.
Easy Scaling – Since the services are decoupled under an event-driven architecture, and as services typically perform only one task, tracking down bottlenecks to a specific service, and scaling that service (and only that service) becomes easy.
Recovery support – An event-driven architecture with a queue can recover lost work by “replaying” events from the past. This can be valuable to prevent data loss when a consumer needs to recover.
Of course, event-driven architectures have drawbacks as well. They are easy to over-engineer by separating concerns that might be simpler when closely coupled; can require a significant upfront investment; and often result in additional complexity in infrastructure, service contracts or schemas, polyglot build systems, and dependency graphs.
Perhaps the most significant drawback and challenge is data and transaction management. Because of their asynchronous nature, event-driven models must carefully handle inconsistent data between services, incompatible versions, watch for duplicate events, and typically do not support ACID transactions, instead supporting eventual consistency which can be more difficult to track or debug.
Even with these drawbacks, an event-driven architecture is usually the better choice for enterprise-level microservice systems. The pros—scalable, loosely coupled, dev-ops friendly design—outweigh the cons.
When to Use REST
There are, however, times when a REST/web interface may still be preferable:
- You need a time-bound request/reply interface
- Convenient support for transactions
- Your API is available to the public
- Your project is small (REST is much simpler to set up and deploy)
Your Most Important Design Choice – Messaging Framework
Once you’ve decided on an event-driven architecture, it is time to choose your event framework. The way your events are produced and consumed is a key factor in your system. Dozens of proven frameworks and choices exist and choosing the right one takes time and research.
Your basic choice comes down to message processing or stream processing.
Message Processing
In traditional message processing, a component creates a message then sends it to a specific (and typically single) destination. The receiving component, which has been sitting idle and waiting, receives the message and acts accordingly. Typically, when the message arrives, the receiving component performs a single process. Then, the message is deleted.
A typical example of a message processing architecture is a Message Queue. Though most newer projects use stream processing (as described below), architectures using message (or event) queues are still popular. Message queues typically use a “store and forward” system of brokers where events travel from broker to broker until they reach the appropriate consumer. ActiveMQ and RabbitMQ are two popular examples of message queue frameworks. Both of these projects have years of proven use and established communities.
Stream Processing
On the other hand, in stream processing, components emit events when they reach a certain state. Other interested components listen for these events on the event stream and react accordingly. Events are not targeted to a certain recipient, but rather are available to all interested components.
In stream processing, components can react to multiple events at the same time, and apply complex operations on multiple streams and events. Some streams include persistence where events stay on the stream for as long as necessary.
With stream processing, a system can reproduce a history of events, come online after the event occurred and still react to it, and even perform sliding window computations. For example, it could calculate the average CPU usage per minute from a stream of per-second events.
One of the most popular stream processing frameworks is Apache Kafka. Kafka is a mature and stable solution used by many projects. It can be considered a go-to, industrial-strength stream processing solution. Kafka has a large userbase, a helpful community, and an evolved toolset.
Other Choices
There are other frameworks that offer either a combination of stream and message processing or their own unique solution. For example, Pulsar, a newer offering from Apache, is an open-source pub/sub messaging system that supports both streams and event queues, all with extremely high performance. Pulsar is feature-rich—it offers multi-tenancy and geo-replication—and accordingly complex. It’s been said that Kafka aims for high throughput, while Pulsar aims for low latency.
NATS is an alternative pub/sub messaging system with “synthetic” queueing. NATS is designed for sending small, frequent messages. It offers both high performance and low latency. However, NATS considers some level of data loss to be acceptable, prioritizing performance over delivery guarantees.
Other Design Considerations
Once you’ve selected your event framework, here are several other challenges to consider:
Event Sourcing
It is difficult to implement a combination of loosely-coupled services, distinct data stores, and atomic transactions. One pattern that may help is Event Sourcing. In Event Sourcing, updates and deletes are never performed directly on the data; rather, state changes of an entity are saved as a series of events.
CQRS
The above event sourcing introduces another issue: Since state needs to be built from a series of events, queries can be slow and complex. Command Query Responsibility Segregation (CQRS) is a design solution that calls for separate models for insert operations and read operations.
Discovering Event Information
One of the greatest challenges in event-driven architecture is cataloging services and events. Where do you find event descriptions and details? What is the reason for an event? What team created the event? Are they actively working on it?
Dealing with Change
Will an event schema change? How do you change an event schema without breaking other services? How you answer these questions becomes critical as your number of services and events grows.
Being a good event consumer means coding for schemas that change. Being a good event producer means being cognizant of how your schema changes impact other services and creating well-designed events that are documented clearly.
On Premise vs Hosted Deployment
Regardless of your event framework, you’ll also need to decide between deploying the framework yourself on premise (message brokers are not trivial to operate, especially with high availability), or using a hosted service such as Apache Kafka on Heroku.
Anti-Patterns
As with most architectures, an event-driven architecture comes with its own set of anti-patterns. Here are a few to watch out for.
Too much of a good thing
Be careful you don’t get too excited about creating events. Creating too many events will create unnecessary complexity between the services, increase cognitive load for developers, make deployment and testing more difficult, and cause congestion for event consumers. Not every method needs to be an event.
Generic events
Don’t use generic events, either in name or in purpose. You want other teams to understand why your event exists, what it should be used for, and when it should be used. Events should have a specific purpose and be named accordingly. Events with generic names, or generic events with confusing flags, cause issues.
Complex dependency graphs
Watch out for services that depend on one another and create complex dependency graphs or feedback loops. Each network hop adds additional latency to the original request, particularly north/south network traffic that leaves the datacenter.
Depending on guaranteed order, delivery, or side effects
Events are asynchronous; therefore, including assumptions of order or duplicates will not only add complexity but will negate many of the key benefits of event-based architecture. If your consumer has side effects, such as adding a value in a database, then you may be unable to recover by replaying events.
Premature optimization
Most products start off small and grow over time. While you may dream of future needs to scale to a large complex organization, if your team is small then the added complexity of event-driven architectures may actually slow you down. Instead, consider designing your system with a simple architecture but include the necessary separation of concerns so that you can swap it out as your needs grow.
Expecting event-driven to fix everything
On a less technical level, don’t expect event-driven architecture to fix all your problems. While this architecture can certainly improve many areas of technical dysfunction, it can’t fix core problems such as a lack of automated testing, poor team communication, or outdated dev-ops practices.
Patterns of Enterprise Architecture Applications
Базовые паттерны
- Mapper (Распределитель)
- Money (Деньги)
- Special Case (Особый Случай)
- Plugin (Плагин)
- Gateway (Шлюз)
- Separated Interface (Выделенный интерфейс)
- Registry (Реестр)
- Service Stub (Сервисная заглушка)
- Value Object (Объект-значение)
- Record Set ()
- Layer Supertype (Супертип Уровня)
- Singleton (Одиночка)
Паттерны веб-представления
- Transform View (Преобразователь)
- Template View (Шаблонизатор)
- Application Controller (Контроллер приложения)
- Two Step View (Двухшаговая шаблонизация)
- Page Controller (Контроллер страницы)
- Front Controller (Контроллер входа / Единая точка входа)
- MVC - Model View Controller (Модель-Вид-Контроллер)
Паттерны архитектуры источников данных
- Row Data Gateway (Шлюз к данным записи)
- Active Record (Активная запись)
- Table Data Gateway (Шлюз к данным таблицы)
- Data Mapper ()
Паттерны Объектно-Реляционной логики
- Lazy Load (Ленивая загрузка)
- Identity Map (Карта присутствия / Карта соответствия)
- Unit of Work (Единица работы)
Паттерны Объектно-Реляционного структурирования
- Identity Field (Поле первичного ключа)
- Foreign Key Mapping (Разметка внешних ключей)
- Association Table Mapping (Разметка таблиц связей)
- Dependent Mapping (Управление распределением подчинённых сущностей)
- Embedded Value (Объединённое свойство)
- Serialized LOB (Сериализованный LOB)
- Single Table Inheritance (Наследование с единой таблицей)
- Class Table Inheritance (Наследование с таблицами классов)
- Concrete Table Inheritance (Наследование с таблицами конечных классов)
- Inherritance Mappers (Наследуемые распределители)
Паттерны логики сущности
- Transaction Script (Сценнарий транзакции)
- Domain Model (Модель области определения)
- Table Module (Обработчик таблицы)
- Service Layer (Сервисный уровень)
Паттерны обработки Объектно-Реляционных метаданных
- Metadata Mapping (Распределение на основе метаданных)
- Query Object (Объект-запрос)
- Repository (Репозиторий)
Паттерны распределения данных
- Remote Facade (Парадный вход)
- Data Transfer Object (Объект передачи данных)
Паттерны локальной конкуренции
- Optimistic Offline Lock (Оптимистичная блокировка)
- Pessimistic Offline Lock (Пессимистичная блокировка)
- Coarse Grained Lock (Грубая блокировка)
- Implicit Lock (Скрытая блокировка)
Architecture Qualities
- Availability tactics
- Modifiability tactics
- Performance tactics
- Security tactics
- Testability tactics
- Usability tactics
Introducing Tactics
What is it that imparts portability to one design, high performance to another, and integrability to a third? The achievement of these qualities relies on fundamental design decisions. We will examine these design decisions, which we call tactics. A tactic is a design decision that influences the control of a quality attribute response. We call a collection of tactics an architectural strategy.
A system design consists of a collection of decisions. Some of these decisions help control the quality attribute responses; others ensure achievement of system functionality.
Each tactic is a design option for the architect. For example, one of the tactics introduces redundancy to increase the availability of a system. This is one option the architect has to increase availability, but not the only one. Usually achieving high availability through redundancy implies a concomitant need for synchronization (to ensure that the redundant copy can be used if the original fails). We see two immediate ramifications of this example.
Tactics can refine other tactics. We identified redundancy as a tactic. As such, it can be refined into redundancy of data (in a database system) or redundancy of computation (in an embedded control system). Both types are also tactics. There are further refinements that a designer can employ to make each type of redundancy more concrete. For each quality attribute that we discuss, we organize the tactics as a hierarchy.
Patterns package tactics. A pattern that supports availability will likely use both a redundancy tactic and a synchronization tactic. It will also likely use more concrete versions of these tactics. At the end of this section, we present an example of a pattern described in terms of its tactics.
Availability Tactics
A failure occurs when the system no longer delivers a service that is consistent with its specification; this failure is observable by the system's users. A fault (or combination of faults) has the potential to cause a failure. Recall also that recovery or repair is an important aspect of availability. The tactics we discuss in this section will keep faults from becoming failures or at least bound the effects of the fault and make repair possible.
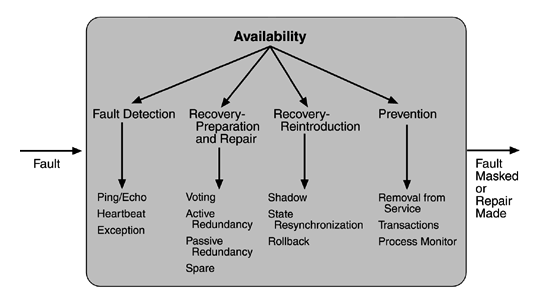
FAULT DETECTION
Three widely used tactics for recognizing faults are ping/echo, heartbeat, and exceptions.
Ping/echo. One component issues a ping and expects to receive back an echo, within a predefined time, from the component under scrutiny. This can be used within a group of components mutually responsible for one task. It can also used be used by clients to ensure that a server object and the communication path to the server are operating within the expected performance bounds. "Ping/echo" fault detectors can be organized in a hierarchy, in which a lowest-level detector pings the software processes with which it shares a processor, and the higher-level fault detectors ping lower-level ones. This uses less communications bandwidth than a remote fault detector that pings all processes.
Heartbeat (dead man timer). In this case one component emits a heartbeat message periodically and another component listens for it. If the heartbeat fails, the originating component is assumed to have failed and a fault correction component is notified. The heartbeat can also carry data. For example, an automated teller machine can periodically send the log of the last transaction to a server. This message not only acts as a heartbeat but also carries data to be processed.
Exceptions. One method for recognizing faults is to encounter an exception, which is raised when one of the fault classes we discussed in Chapter 4 is recognized. The exception handler typically executes in the same process that introduced the exception.
The ping/echo and heartbeat tactics operate among distinct processes, and the exception tactic operates within a single process. The exception handler will usually perform a semantic transformation of the fault into a form that can be processed.
FAULT RECOVERY
Fault recovery consists of preparing for recovery and making the system repair. Some preparation and repair tactics follow.
- Voting. Processes running on redundant processors each take equivalent input and compute a simple output value that is sent to a voter. If the voter detects deviant behavior from a single processor, it fails it. The voting algorithm can be "majority rules" or "preferred component" or some other algorithm. This method is used to correct faulty operation of algorithms or failure of a processor and is often used in control systems. If all of the processors utilize the same algorithms, the redundancy detects only a processor fault and not an algorithm fault. Thus, if the consequence of a failure is extreme, such as potential loss of life, the redundant components can be diverse.
One extreme of diversity is that the software for each redundant component is developed by different teams and executes on dissimilar platforms. Less extreme is to develop a single software component on dissimilar platforms. Diversity is expensive to develop and maintain and is used only in exceptional circumstances, such as the control of surfaces on aircraft. It is usually used for control systems in which the outputs to the voter are straightforward and easy to classify as equivalent or deviant, the computations are cyclic, and all redundant components receive equivalent inputs from sensors. Diversity has no downtime when a failure occurs since the voter continues to operate. Variations on this approach include the Simplex approach, which uses the results of a "preferred" component unless they deviate from those of a "trusted" component, to which it defers. Synchronization among the redundant components is automatic since they are all assumed to be computing on the same set of inputs in parallel.
- Active redundancy (hot restart). All redundant components respond to events in parallel. Consequently, they are all in the same state. The response from only one component is used (usually the first to respond), and the rest are discarded. When a fault occurs, the downtime of systems using this tactic is usually milliseconds since the backup is current and the only time to recover is the switching time. Active redundancy is often used in a client/server configuration, such as database management systems, where quick responses are necessary even when a fault occurs. In a highly available distributed system, the redundancy may be in the communication paths. For example, it may be desirable to use a LAN with a number of parallel paths and place each redundant component in a separate path. In this case, a single bridge or path failure will not make all of the system's components unavailable.
Synchronization is performed by ensuring that all messages to any redundant component are sent to all redundant components. If communication has a possibility of being lost (because of noisy or overloaded communication lines), a reliable transmission protocol can be used to recover. A reliable transmission protocol requires all recipients to acknowledge receipt together with some integrity indication such as a checksum. If the sender cannot verify that all recipients have received the message, it will resend the message to those components not acknowledging receipt. The resending of unreceived messages (possibly over different communication paths) continues until the sender marks the recipient as out of service.
- Passive redundancy (warm restart/dual redundancy/triple redundancy). One component (the primary) responds to events and informs the other components (the standbys) of state updates they must make. When a fault occurs, the system must first ensure that the backup state is sufficiently fresh before resuming services. This approach is also used in control systems, often when the inputs come over communication channels or from sensors and have to be switched from the primary to the backup on failure. Chapter 6, describing an air traffic control example, shows a system using it. In the air traffic control system, the secondary decides when to take over from the primary, but in other systems this decision can be done in other components. This tactic depends on the standby components taking over reliably. Forcing switchovers periodically—for example, once a day or once a week—increases the availability of the system. Some database systems force a switch with storage of every new data item. The new data item is stored in a shadow page and the old page becomes a backup for recovery. In this case, the downtime can usually be limited to seconds.
Synchronization is the responsibility of the primary component, which may use atomic broadcasts to the secondaries to guarantee synchronization.
- Spare. A standby spare computing platform is configured to replace many different failed components. It must be rebooted to the appropriate software configuration and have its state initialized when a failure occurs. Making a checkpoint of the system state to a persistent device periodically and logging all state changes to a persistent device allows for the spare to be set to the appropriate state. This is often used as the standby client workstation, where the user can move when a failure occurs. The downtime for this tactic is usually minutes.
There are tactics for repair that rely on component reintroduction. When a redundant component fails, it may be reintroduced after it has been corrected. Such tactics are shadow operation, state resynchronization, and rollback.
Shadow operation. A previously failed component may be run in "shadow mode" for a short time to make sure that it mimics the behavior of the working components before restoring it to service.
State resynchronization. The passive and active redundancy tactics require the component being restored to have its state upgraded before its return to service. The updating approach will depend on the downtime that can be sustained, the size of the update, and the number of messages required for the update. A single message containing the state is preferable, if possible. Incremental state upgrades, with periods of service between increments, lead to complicated software.
Checkpoint/rollback. A checkpoint is a recording of a consistent state created either periodically or in response to specific events. Sometimes a system fails in an unusual manner, with a detectably inconsistent state. In this case, the system should be restored using a previous checkpoint of a consistent state and a log of the transactions that occurred since the snapshot was taken.
FAULT PREVENTION
The following are some fault prevention tactics.
Removal from service. This tactic removes a component of the system from operation to undergo some activities to prevent anticipated failures. One example is rebooting a component to prevent memory leaks from causing a failure. If this removal from service is automatic, an architectural strategy can be designed to support it. If it is manual, the system must be designed to support it.
Transactions. A transaction is the bundling of several sequential steps such that the entire bundle can be undone at once. Transactions are used to prevent any data from being affected if one step in a process fails and also to prevent collisions among several simultaneous threads accessing the same data.
Process monitor. Once a fault in a process has been detected, a monitoring process can delete the nonperforming process and create a new instance of it, initialized to some appropriate state as in the spare tactic.
Modifiability Tactics
We organize the tactics for modifiability in sets according to their goals. One set has as its goal reducing the number of modules that are directly affected by a change. We call this set "localize modifications." A second set has as its goal limiting modifications to the localized modules. We use this set of tactics to "prevent the ripple effect." Implicit in this distinction is that there are modules directly affected (those whose responsibilities are adjusted to accomplish the change) and modules indirectly affected by a change (those whose responsibilities remain unchanged but whose implementation must be changed to accommodate the directly affected modules). A third set of tactics has as its goal controlling deployment time and cost. We call this set "defer binding time."
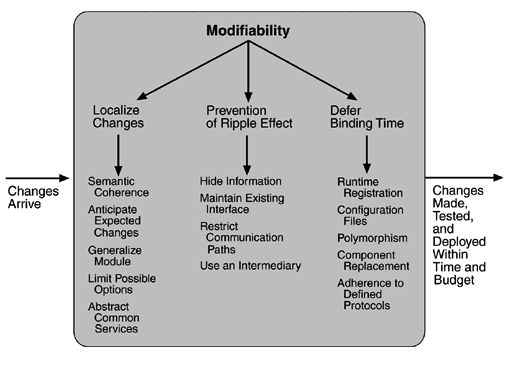
LOCALIZE MODIFICATIONS
Although there is not necessarily a precise relationship between the number of modules affected by a set of changes and the cost of implementing those changes, restricting modifications to a small set of modules will generally reduce the cost. The goal of tactics in this set is to assign responsibilities to modules during design such that anticipated changes will be limited in scope. We identify five such tactics.
Maintain semantic coherence. Semantic coherence refers to the relationships among responsibilities in a module. The goal is to ensure that all of these responsibilities work together without excessive reliance on other modules. Achievement of this goal comes from choosing responsibilities that have semantic coherence. Coupling and cohesion metrics are an attempt to measure semantic coherence, but they are missing the context of a change. Instead, semantic coherence should be measured against a set of anticipated changes. One subtactic is to abstract common services. Providing common services through specialized modules is usually viewed as supporting re-use. This is correct, but abstracting common services also supports modifiability. If common services have been abstracted, modifications to them will need to be made only once rather than in each module where the services are used. Furthermore, modification to the modules using those services will not impact other users. This tactic, then, supports not only localizing modifications but also the prevention of ripple effects. Examples of abstracting common services are the use of application frameworks and the use of other middleware software.
Anticipate expected changes. Considering the set of envisioned changes provides a way to evaluate a particular assignment of responsibilities. The basic question is "For each change, does the proposed decomposition limit the set of modules that need to be modified to accomplish it?" An associated question is "Do fundamentally different changes affect the same modules?" How is this different from semantic coherence? Assigning responsibilities based on semantic coherence assumes that expected changes will be semantically coherent. The tactic of anticipating expected changes does not concern itself with the coherence of a module's responsibilities but rather with minimizing the effects of the changes. In reality this tactic is difficult to use by itself since it is not possible to anticipate all changes. For that reason, it is usually used in conjunction with semantic coherence.
Generalize the module. Making a module more general allows it to compute a broader range of functions based on input. The input can be thought of as defining a language for the module, which can be as simple as making constants input parameters or as complicated as implementing the module as an interpreter and making the input parameters be a program in the interpreter's language. The more general a module, the more likely that requested changes can be made by adjusing the input language rather than by modifying the module.
Limit possible options. Modifications, especially within a product line (see Chapter 14), may be far ranging and hence affect many modules. Restricting the possible options will reduce the effect of these modifications. For example, a variation point in a product line may be allowing for a change of processor. Restricting processor changes to members of the same family limits the possible options.
PREVENT RIPPLE EFFECTS
A ripple effect from a modification is the necessity of making changes to modules not directly affected by it. For instance, if module A is changed to accomplish a particular modification, then module B is changed only because of the change to module A. B has to be modified because it depends, in some sense, on A.
We begin our discussion of the ripple effect by discussing the various types of dependencies that one module can have on another. We identify eight types:
- Syntax of
data. For B to compile (or execute) correctly, the type (or format) of the data that is produced by A and consumed by B must be consistent with the type (or format) of data assumed by B.
service. For B to compile and execute correctly, the signature of services provided by A and invoked by B must be consistent with the assumptions of B.
- Semantics of
data. For B to execute correctly, the semantics of the data produced by A and consumed by B must be consistent with the assumptions of B.
service. For B to execute correctly, the semantics of the services produced by A and used by B must be consistent with the assumptions of B.
- Sequence of
data. For B to execute correctly, it must receive the data produced by A in a fixed sequence. For example, a data packet's header must precede its body in order of reception (as opposed to protocols that have the sequence number built into the data).
control. For B to execute correctly, A must have executed previously within certain timing constraints. For example, A must have executed no longer than 5ms before B executes.
Identity of an interface of A. A may have multiple interfaces. For B to compile and execute correctly, the identity (name or handle) of the interface must be consistent with the assumptions of B.
Location of A (runtime). For B to execute correctly, the runtime location of A must be consistent with the assumptions of B. For example, B may assume that A is located in a different process on the same processor.
Quality of service/data provided by A. For B to execute correctly, some property involving the quality of the data or service provided by A must be consistent with B's assumptions. For example, data provided by a particular sensor must have a certain accuracy in order for the algorithms of B to work correctly.
Existence of A. For B to execute correctly, A must exist. For example, if B is requesting a service from an object A, and A does not exist and cannot be dynamically created, then B will not execute correctly.
Resource behavior of A. For B to execute correctly, the resource behavior of A must be consistent with B's assumptions. This can be either resource usage of A (A uses the same memory as B) or resource ownership (B reserves a resource that A believes it owns).
With this understanding of dependency types, we can now discuss tactics available to the architect for preventing the ripple effect for certain types.
Notice that none of our tactics necessarily prevent the ripple of semantic changes. We begin with discussion of those that are relevant to the interfaces of a particular module—information hiding and maintaining existing interfaces—and follow with one that breaks a dependency chain—use of an intermediary.
Hide information. Information hiding is the decomposition of the responsibilities for an entity (a system or some decomposition of a system) into smaller pieces and choosing which information to make private and which to make public. The public responsibilities are available through specified interfaces. The goal is to isolate changes within one module and prevent changes from propagating to others. This is the oldest technique for preventing changes from propagating. It is strongly related to "anticipate expected changes" because it uses those changes as the basis for decomposition.
Maintain existing interfaces. If B depends on the name and signature of an interface of A, maintaining this interface and its syntax allows B to remain unchanged. Of course, this tactic will not necessarily work if B has a semantic dependency on A, since changes to the meaning of data and services are difficult to mask. Also, it is difficult to mask dependencies on quality of data or quality of service, resource usage, or resource ownership. Interface stability can also be achieved by separating the interface from the implementation. This allows the creation of abstract interfaces that mask variations. Variations can be embodied within the existing responsibilities, or they can be embodied by replacing one implementation of a module with another.
Patterns that implement this tactic include
adding interfaces. Most programming languages allow multiple interfaces. Newly visible services or data can be made available through new interfaces, allowing existing interfaces to remain unchanged and provide the same signature.
adding adapter. Add an adapter to A that wraps A and provides the signature of the original A.
providing a stub A. If the modification calls for the deletion of A, then providing a stub for A will allow B to remain unchanged if B depends only on A's signature.
Restrict communication paths. Restrict the modules with which a given module shares data. That is, reduce the number of modules that consume data produced by the given module and the number of modules that produce data consumed by it. This will reduce the ripple effect since data production/consumption introduces dependencies that cause ripples. Chapter 8 (Flight Simulation) discusses a pattern that uses this tactic.
Use an intermediary. If B has any type of dependency on A other than semantic, it is possible to insert an intermediary between B and A that manages activities associated with the dependency. All of these intermediaries go by different names, but we will discuss each in terms of the dependency types we have enumerated. As before, in the worst case, an intermediary cannot compensate for semantic changes. The intermediaries are
***data (syntax)***. Repositories (both blackboard and passive) act as intermediaries between the producer and consumer of data. The repositories can convert the syntax produced by A into that assumed by B. Some publish/subscribe patterns (those that have data flowing through a central component) can also convert the syntax into that assumed by B. The MVC and PAC patterns convert data in one formalism (input or output device) into another (that used by the model in MVC or the abstraction in PAC).
***service (syntax)***. The facade, bridge, mediator, strategy, proxy, and factory patterns all provide intermediaries that convert the syntax of a service from one form into another. Hence, they can all be used to prevent changes in A from propagating to B.
identity of an interface of A. A broker pattern can be used to mask changes in the identity of an interface. If B depends on the identity of an interface of A and that identity changes, by adding that identity to the broker and having the broker make the connection to the new identity of A, B can remain unchanged.
***location of A (runtime)***. A name server enables the location of A to be changed without affecting B. A is responsible for registering its current location with the name server, and B retrieves that location from the name server.
resource behavior of A or resource controlled by A. A resource manager is an intermediary that is responsible for resource allocation. Certain resource managers (e.g., those based on Rate Monotonic Analysis in real-time systems) can guarantee the satisfaction of all requests within certain constraints. A, of course, must give up control of the resource to the resource manager.
existence of A. The factory pattern has the ability to create instances as needed, and thus the dependence of B on the existence of A is satisfied by actions of the factory.
DEFER BINDING TIME
The two tactic categories we have discussed thus far are designed to minimize the number of modules that require changing to implement modifications. Our modifiability scenarios include two elements that are not satisfied by reducing the number of modules to be changed—time to deploy and allowing nondevelopers to make changes. Deferring binding time supports both of those scenarios at the cost of requiring additional infrastructure to support the late binding.
Decisions can be bound into the executing system at various times. We discuss those that affect deployment time. The deployment of a system is dictated by some process. When a modification is made by the developer, there is usually a testing and distribution process that determines the time lag between the making of the change and the availability of that change to the end user. Binding at runtime means that the system has been prepared for that binding and all of the testing and distribution steps have been completed. Deferring binding time also supports allowing the end user or system administrator to make settings or provide input that affects behavior.
Many tactics are intended to have impact at loadtime or runtime, such as the following.
Runtime registration supports plug-and-play operation at the cost of additional overhead to manage the registration. Publish/subscribe registration, for example, can be implemented at either runtime or load time.
Configuration files are intended to set parameters at startup.
Polymorphism allows late binding of method calls.
Component replacement allows load time binding.
Adherence to defined protocols allows runtime binding of independent processes.
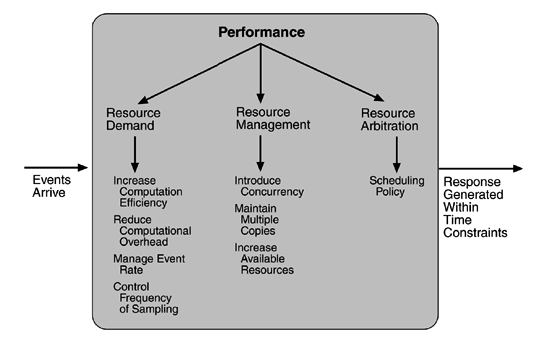
Performance tactics
the goal of performance tactics is to generate a response to an event arriving at the system within some time constraint. The event can be single or a stream and is the trigger for a request to perform computation. It can be the arrival of a message, the expiration of a time interval, the detection of a significant change of state in the system's environment, and so forth. The system processes the events and generates a response. Performance tactics control the time within which a response is generated.
After an event arrives, either the system is processing on that event or the processing is blocked for some reason. This leads to the two basic contributors to the response time: resource consumption and blocked time.
Resource consumption. Resources include CPU, data stores, network communication bandwidth, and memory, but it can also include entities defined by the particular system under design. For example, buffers must be managed and access to critical sections must be made sequential. Events can be of varying types (as just enumerated), and each type goes through a processing sequence. For example, a message is generated by one component, is placed on the network, and arrives at another component. It is then placed in a buffer; transformed in some fashion (marshalling is the term the Object Management Group uses for this transformation); processed according to some algorithm; transformed for output; placed in an output buffer; and sent onward to another component, another system, or the user. Each of these phases contributes to the overall latency of the processing of that event.
Blocked time. A computation can be blocked from using a resource because of contention for it, because the resource is unavailable, or because the computation depends on the result of other computations that are not yet available.
Contention for resources. Figure 5.6 shows events arriving at the system. These events may be in a single stream or in multiple streams. Multiple streams vying for the same resource or different events in the same stream vying for the same resource contribute to latency. In general, the more contention for a resource, the more likelihood of latency being introduced. However, this depends on how the contention is arbitrated and how individual requests are treated by the arbitration mechanism.
Availability of resources. Even in the absence of contention, computation cannot proceed if a resource is unavailable. Unavailability may be caused by the resource being offline or by failure of the component or for some other reason. In any case, the architect must identify places where resource unavailability might cause a significant contribution to overall latency.
Dependency on other computation. A computation may have to wait because it must synchronize with the results of another computation or because it is waiting for the results of a computation that it initiated. For example, it may be reading information from two different sources, if these two sources are read sequentially, the latency will be higher than if they are read in parallel.
With this background, we turn to our three tactic categories: resource demand, resource management, and resource arbitration.
RESOURCE DEMAND
Event streams are the source of resource demand. Two characteristics of demand are the time between events in a resource stream (how often a request is made in a stream) and how much of a resource is consumed by each request.
One tactic for reducing latency is to reduce the resources required for processing an event stream. Ways to do this include the following.
Increase computational efficiency. One step in the processing of an event or a message is applying some algorithm. Improving the algorithms used in critical areas will decrease latency. Sometimes one resource can be traded for another. For example, intermediate data may be kept in a repository or it may be regenerated depending on time and space resource availability. This tactic is usually applied to the processor but is also effective when applied to other resources such as a disk.
Reduce computational overhead. If there is no request for a resource, processing needs are reduced. In Chapter 17, we will see an example of using Java classes rather than Remote Method Invocation (RMI) because the former reduces communication requirements. The use of intermediaries (so important for modifiability) increases the resources consumed in processing an event stream, and so removing them improves latency. This is a classic modifiability/performance tradeoff.
Another tactic for reducing latency is to reduce the number of events processed. This can be done in one of two fashions.
Manage event rate. If it is possible to reduce the sampling frequency at which environmental variables are monitored, demand can be reduced. Sometimes this is possible if the system was overengineered. Other times an unnecessarily high sampling rate is used to establish harmonic periods between multiple streams. That is, some stream or streams of events are oversampled so that they can be synchronized.
Control frequency of sampling. If there is no control over the arrival of externally generated events, queued requests can be sampled at a lower frequency, possibly resulting in the loss of requests.
Other tactics for reducing or managing demand involve controlling the use of resources.
Bound execution times. Place a limit on how much execution time is used to respond to an event. Sometimes this makes sense and sometimes it does not. For iterative, data-dependent algorithms, limiting the number of iterations is a method for bounding execution times.
Bound queue sizes. This controls the maximum number of queued arrivals and consequently the resources used to process the arrivals.
RESOURCE MANAGEMENT
Even though the demand for resources may not be controllable, the management of these resources affects response times. Some resource management tactics are:
Introduce concurrency. If requests can be processed in parallel, the blocked time can be reduced. Concurrency can be introduced by processing different streams of events on different threads or by creating additional threads to process different sets of activities. Once concurrency has been introduced, appropriately allocating the threads to resources (load balancing) is important in order to maximally exploit the concurrency.
Maintain multiple copies of either data or computations. Clients in a client-server pattern are replicas of the computation. The purpose of replicas is to reduce the contention that would occur if all computations took place on a central server. Caching is a tactic in which data is replicated, either on different speed repositories or on separate repositories, to reduce contention. Since the data being cached is usually a copy of existing data, keeping the copies consistent and synchronized becomes a responsibility that the system must assume.
Increase available resources. Faster processors, additional processors, additional memory, and faster networks all have the potential for reducing latency. Cost is usually a consideration in the choice of resources, but increasing the resources is definitely a tactic to reduce latency. This kind of cost/performance tradeoff is analyzed in Chapter 12.
RESOURCE ARBITRATION
Whenever there is contention for a resource, the resource must be scheduled. Processors are scheduled, buffers are scheduled, and networks are scheduled. The architect's goal is to understand the characteristics of each resource's use and choose the scheduling strategy that is compatible with it.
A scheduling policy conceptually has two parts: a priority assignment and dispatching. All scheduling policies assign priorities. In some cases the assignment is as simple as first-in/first-out. In other cases, it can be tied to the deadline of the request or its semantic importance. Competing criteria for scheduling include optimal resource usage, request importance, minimizing the number of resources used, minimizing latency, maximizing throughput, preventing starvation to ensure fairness, and so forth. The architect needs to be aware of these possibly conflicting criteria and the effect that the chosen tactic has on meeting them.
A high-priority event stream can be dispatched only if the resource to which it is being assigned is available. Sometimes this depends on pre-empting the current user of the resource. Possible preemption options are as follows: can occur anytime; can occur only at specific pre-emption points; and executing processes cannot be pre-empted. Some common scheduling policies are:
First-in/First-out. FIFO queues treat all requests for resources as equals and satisfy them in turn. One possibility with a FIFO queue is that one request will be stuck behind another one that takes a long time to generate a response. As long as all of the requests are truly equal, this is not a problem, but if some requests are of higher priority than others, it is problematic.
Fixed-priority scheduling. Fixed-priority scheduling assigns each source of resource requests a particular priority and assigns the resources in that priority order. This strategy insures better service for higher-priority requests but admits the possibility of a low-priority, but important, request taking an arbitrarily long time to be serviced because it is stuck behind a series of higher-priority requests. Three common prioritization strategies are
semantic importance. Each stream is assigned a priority statically according to some domain characteristic of the task that generates it. This type of scheduling is used in mainframe systems where the domain characteristic is the time of task initiation.
deadline monotonic. Deadline monotonic is a static priority assignment that assigns higher priority to streams with shorter deadlines. This scheduling policy is used when streams of different priorities with real-time deadlines are to be scheduled.
rate monotonic. Rate monotonic is a static priority assignment for periodic streams that assigns higher priority to streams with shorter periods. This scheduling policy is a special case of deadline monotonic but is better known and more likely to be supported by the operating system.
- Dynamic priority scheduling:
round robin. Round robin is a scheduling strategy that orders the requests and then, at every assignment possibility, assigns the resource to the next request in that order. A special form of round robin is a cyclic executive where assignment possibilities are at fixed time intervals.
earliest deadline first. Earliest deadline first assigns priorities based on the pending requests with the earliest deadline.
- Static scheduling. A cyclic executive schedule is a scheduling strategy where the pre-emption points and the sequence of assignment to the resource are determined offline.
Security Tactics
Tactics for achieving security can be divided into those concerned with resisting attacks, those concerned with detecting attacks, and those concerned with recovering from attacks. All three categories are important. Using a familiar analogy, putting a lock on your door is a form of resisting an attack, having a motion sensor inside of your house is a form of detecting an attack, and having insurance is a form of recovering from an attack
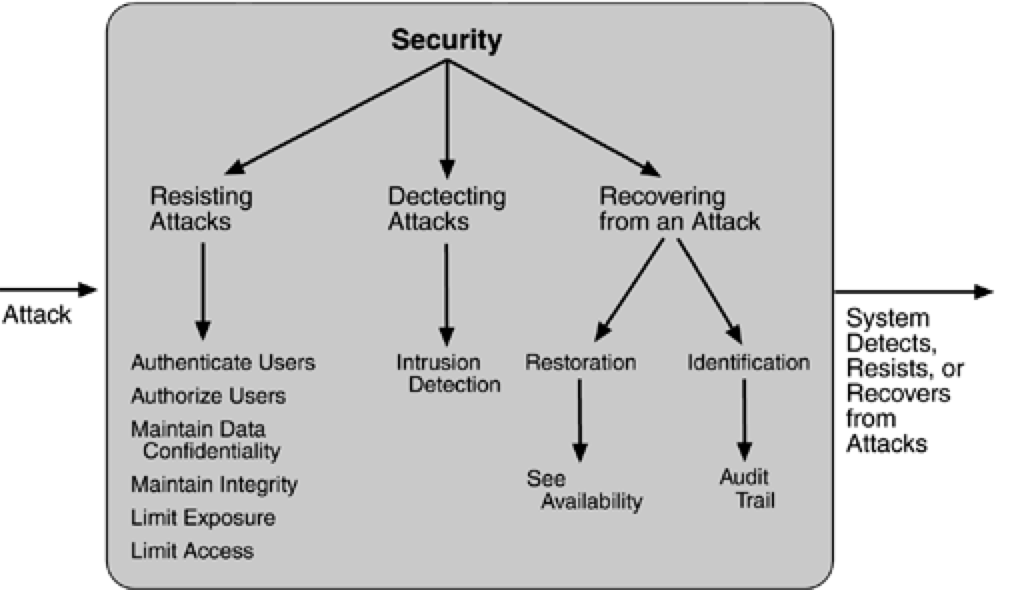
RESISTING ATTACKS
Authenticate users. Authentication is ensuring that a user or remote computer is actually who it purports to be. Passwords, one-time passwords, digital certificates, and biometric identifications provide authentication.
Authorize users. Authorization is ensuring that an authenticated user has the rights to access and modify either data or services. This is usually managed by providing some access control patterns within a system. Access control can be by user or by user class. Classes of users can be defined by user groups, by user roles, or by lists of individuals.
Maintain data confidentiality. Data should be protected from unauthorized access. Confidentiality is usually achieved by applying some form of encryption to data and to communication links. Encryption provides extra protection to persistently maintained data beyond that available from authorization. Communication links, on the other hand, typically do not have authorization controls. Encryption is the only protection for passing data over publicly accessible communication links. The link can be implemented by a virtual private network (VPN) or by a Secure Sockets Layer (SSL) for a Web-based link. Encryption can be symmetric (both parties use the same key) or asymmetric (public and private keys).
Maintain integrity. Data should be delivered as intended. It can have redundant information encoded in it, such as checksums or hash results, which can be encrypted either along with or independently from the original data.
Limit exposure. Attacks typically depend on exploiting a single weakness to attack all data and services on a host. The architect can design the allocation of services to hosts so that limited services are available on each host.
Limit access. Firewalls restrict access based on message source or destination port. Messages from unknown sources may be a form of an attack. It is not always possible to limit access to known sources. A public Web site, for example, can expect to get requests from unknown sources. One configuration used in this case is the so-called demilitarized zone (DMZ). A DMZ is used when access must be provided to Internet services but not to a private network. It sits between the Internet and a firewall in front of the internal network. The DMZ contains devices expected to receive messages from arbitrary sources such as Web services, e-mail, and domain name services.
DETECTING ATTACKS
The detection of an attack is usually through an intrusion detection system. Such systems work by comparing network traffic patterns to a database. In the case of misuse detection, the traffic pattern is compared to historic patterns of known attacks. In the case of anomaly detection, the traffic pattern is compared to a historical baseline of itself. Frequently, the packets must be filtered in order to make comparisons. Filtering can be on the basis of protocol, TCP flags, payload sizes, source or destination address, or port number.
Intrusion detectors must have some sort of sensor to detect attacks, managers to do sensor fusion, databases for storing events for later analysis, tools for offline reporting and analysis, and a control console so that the analyst can modify intrusion detection actions.
RECOVERING FROM ATTACKS
Tactics involved in recovering from an attack can be divided into those concerned with restoring state and those concerned with attacker identification (for either preventive or punitive purposes).
The tactics used in restoring the system or data to a correct state overlap with those used for availability since they are both concerned with recovering a consistent state from an inconsistent state. One difference is that special attention is paid to maintaining redundant copies of system administrative data such as passwords, access control lists, domain name services, and user profile data.
The tactic for identifying an attacker is to maintain an audit trail. An audit trail is a copy of each transaction applied to the data in the system together with identifying information. Audit information can be used to trace the actions of an attacker, support nonrepudiation (it provides evidence that a particular request was made), and support system recovery. Audit trails are often attack targets themselves and therefore should be maintained in a trusted fashion.
Testability Tactics
The goal of tactics for testability is to allow for easier testing when an increment of software development is completed. Architectural techniques for enhancing the software testability have not received as much attention as more mature fields such as modifiability, performance, and availability, but, since testing consumes such a high percentage of system development cost, anything the architect can do to reduce this cost will yield a significant benefit.
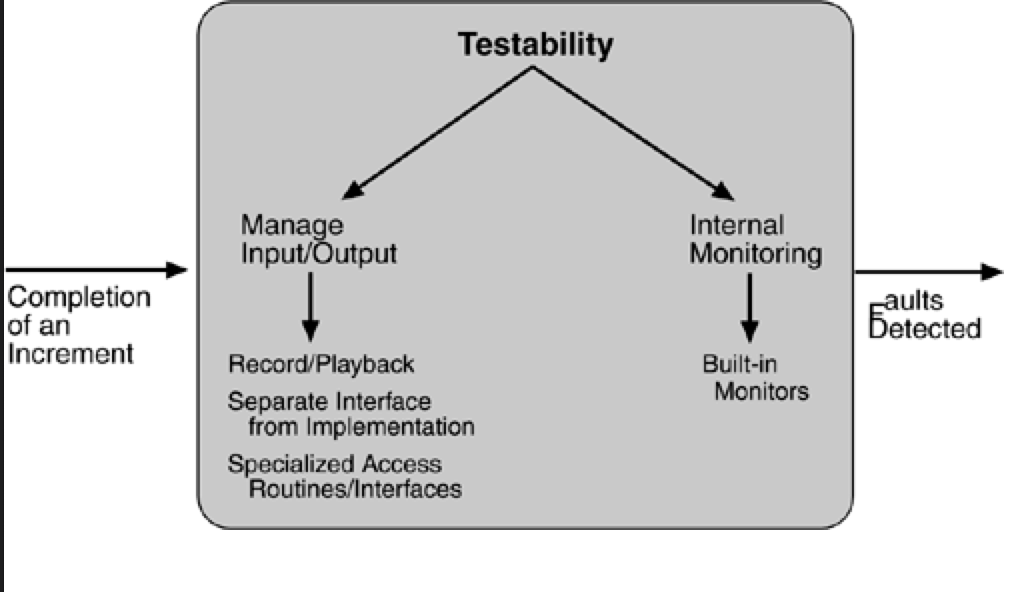
We included design reviews as a testing technique, in this chapter we are concerned only with testing a running system. The goal of a testing regimen is to discover faults. This requires that input be provided to the software being tested and that the output be captured.
Executing the test procedures requires some software to provide input to the software being tested and to capture the output. This is called a test harness. A question we do not consider here is the design and generation of the test harness. In some systems, this takes substantial time and expense.
We discuss two categories of tactics for testing: providing input and capturing output, and internal monitoring.
INPUT/OUTPUT
There are three tactics for managing input and output for testing.
Record/playback. Record/playback refers to both capturing information crossing an interface and using it as input into the test harness. The information crossing an interface during normal operation is saved in some repository and represents output from one component and input to another. Recording this information allows test input for one of the components to be generated and test output for later comparison to be saved.
Separate interface from implementation. Separating the interface from the implementation allows substitution of implementations for various testing purposes. Stubbing implementations allows the remainder of the system to be tested in the absence of the component being stubbed. Substituting a specialized component allows the component being replaced to act as a test harness for the remainder of the system.
Specialize access routes/interfaces. Having specialized testing interfaces allows the capturing or specification of variable values for a component through a test harness as well as independently from its normal execution. For example, metadata might be made available through a specialized interface that a test harness would use to drive its activities. Specialized access routes and interfaces should be kept separate from the access routes and interfaces for required functionality. Having a hierarchy of test interfaces in the architecture means that test cases can be applied at any level in the architecture and that the testing functionality is in place to observe the response.
INTERNAL MONITORING
A component can implement tactics based on internal state to support the testing process.
- Built-in monitors. The component can maintain state, performance load, capacity, security, or other information accessible through an interface. This interface can be a permanent interface of the component or it can be introduced temporarily via an instrumentation technique such as aspect-oriented programming or preprocessor macros. A common technique is to record events when monitoring states have been activated. Monitoring states can actually increase the testing effort since tests may have to be repeated with the monitoring turned off. Increased visibility into the activities of the component usually more than outweigh the cost of the additional testing.
Usability Tactics
Usability is concerned with how easy it is for the user to accomplish a desired task and the kind of support the system provides to the user. Two types of tactics support usability, each intended for two categories of "users." The first category, runtime, includes those that support the user during system execution. The second category is based on the iterative nature of user interface design and supports the interface developer at design time. It is strongly related to the modifiability tactics already presented.
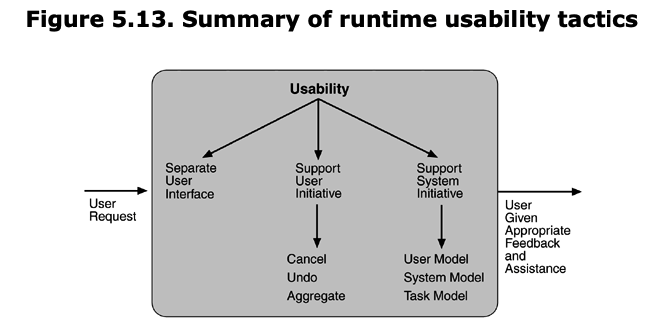
RUNTIME TACTICS
Once a system is executing, usability is enhanced by giving the user feedback as to what the system is doing and by providing the user with the ability to issue usability-based commands. For example, cancel, undo, aggregate, and show multiple views support the user in either error correction or more efficient operations.
Researchers in human–computer interaction have used the terms "user intiative," "system initiative," and "mixed initiative" to describe which of the human–computer pair takes the initiative in performing certain actions and how the interaction proceeds. The usability scenarios we enumerated in Chapter 4, Understanding Quality Attributes, combine initiatives from both perspectives. For example, when canceling a command the user issues a cancel—"user initiative"—and the system responds. During the cancel, however, the system may put up a progress indicator—"system initiative." Thus, cancel demonstrates "mixed initiative." We use this distinction between user and system initiative to discuss the tactics that the architect uses to achieve the various scenarios.
When the user takes the initiative, the architect designs a response as if for any other piece of functionality. The architect must enumerate the responsibilities of the system to respond to the user command. To use the cancel example again: When the user issues a cancel command, the system must be listening for it (thus, there is the responsibility to have a constant listener that is not blocked by the actions of whatever is being canceled); the command to cancel must be killed; any resources being used by the canceled command must be freed; and components that are collaborating with the canceled command must be informed so that they can also take appropriate action.
When the system takes the initiative, it must rely on some information—a model—about the user, the task being undertaken by the user, or the system state itself. Each model requires various types of input to accomplish its initiative. The system initiative tactics are those that identify the models the system uses to predict either its own behavior or the user's intention. Encapsulating this information will enable an architect to more easily tailor and modify those models. Tailoring and modification can be either dynamically based on past user behavior or offline during development.
Maintain a model of the task. In this case, the model maintained is that of the task. The task model is used to determine context so the system can have some idea of what the user is attempting and provide various kinds of assistance. For example, knowing that sentences usually start with capital letters would allow an application to correct a lower-case letter in that position.
Maintain a model of the user. In this case, the model maintained is of the user. It determines the user's knowledge of the system, the user's behavior in terms of expected response time, and other aspects specific to a user or a class of users. For example, maintaining a user model allows the system to pace scrolling so that pages do not fly past faster than they can be read.
Maintain a model of the system. In this case, the model maintained is that of the system. It determines the expected system behavior so that appropriate feedback can be given to the user. The system model predicts items such as the time needed to complete current activity.
DESIGN-TIME TACTICS
User interfaces are typically revised frequently during the testing process. That is, the usability engineer will give the developers revisions to the current user interface design and the developers will implement them. This leads to a tactic that is a refinement of the modifiability tactic of semantic coherence:
Separate the user interface from the rest of the application. Localizing expected changes is the rationale for semantic coherence. Since the user interface is expected to change frequently both during the development and after deployment, maintaining the user interface code separately will localize changes to it. The software architecture patterns developed to implement this tactic and to support the modification of the user interface are:
- Model-View-Controller
- Presentation-Abstraction-Control
- Seeheim
- Arch/Slinky
Microservice architecture
Integration
The Shared Database
By far the most common form of integration that I or any of my colleagues see in the industry is database (DB) integration. In this world, if other services want information from a service, they reach into the database. And if they want to change it, they reach into the database! This is really simple when you first think about it, and is probably the fastest form of integration to start with—which probably explains its popularity.
Figure 4-1 shows our registration UI, which creates customers by performing SQL operations directly on the database. It also shows our call center application that views and edits customer data by running SQL on the database. And the warehouse updates information about customer orders by querying the database. This is a common enough pattern, but it’s one fraught with difficulties.
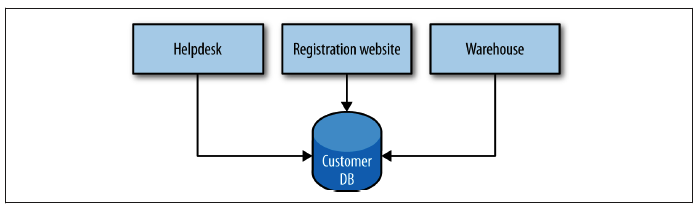
These two different modes of communication can enable two different idiomatic styles of collaboration: request/response or event-based. With request/response, a client initiates a request and waits for the response. This model clearly aligns well to synchronous communication, but can work for asynchronous communication too. I might kick off an operation and register a callback, asking the server to let me know when my operation has completed.
With an event-based collaboration, we invert things. Instead of a client initiating requests asking for things to be done, it instead says this thing happened and expects other parties to know what to do. We never tell anyone else what to do. Event-based systems by their nature are asynchronous. The smarts are more evenly distributed— that is, the business logic is not centralized into core brains, but instead pushed out more evenly to the various collaborators. Event-based collaboration is also highly decoupled. The client that emits an event doesn’t have any way of knowing who or what will react to it, which also means that you can add new subscribers to these events without the client ever needing to know.
Remote Procedure Calls
Remote procedure call refers to the technique of making a local call and having it execute on a remote service somewhere. There are a number of different types of RPC technology out there. Some of this technology relies on having an interface definition (SOAP, Thrift, protocol buffers). The use of a separate interface definition can make it easier to generate client and server stubs for different technology stacks, so, for example,
I could have a Java server exposing a SOAP interface, and a .NET client generated from the Web Service Definition Language (WSDL) definition of the interface. Other technology, like Java RMI, calls for a tighter coupling between the client and server, requiring that both use the same underlying technology but avoid the need for a shared interface definition. All these technologies, however, have the same, core characteristic in that they make a local call look like a remote call.
Many of these technologies are binary in nature, like Java RMI, Thrift, or protocol buffers, while SOAP uses XML for its message formats. Some implementations are tied to a specific networking protocol (like SOAP, which makes nominal use of HTTP), whereas others might allow you to use different types of networking protocols, which themselves can provide additional features. For example, TCP offers guarantees about delivery, whereas UDP doesn’t but has a much lower overhead. This can allow you to use different networking technology for different use cases.
Those RPC implementations that allow you to generate client and server stubs help you get started very, very fast. I can be sending content over a network boundary in no time at all. This is often one of the main selling points of RPC: its ease of use. The fact that I can just make a normal method call and theoretically ignore the rest is a huge boon.
Some RPC implementations, though, do come with some downsides that can cause issues. These issues aren’t always apparent initially, but nonetheless they can be severe enough to outweigh the benefits of being so easy to get up and running quickly.
REST and HTTP
HTTP itself defines some useful capabilities that play very well with the REST style. For example, the HTTP verbs (e.g., GET, POST, and PUT) already have wellunderstood meanings in the HTTP specification as to how they should work with resources. The REST architectural style actually tells us that methods should behave the same way on all resources, and the HTTP specification happens to define a bunch of methods we can use. GET retrieves a resource in an idempotent way, and POST creates a new resource. This means we can avoid lots of different createCustomer or editCustomer methods. Instead, we can simply POST a customer representation to request that the server create a new resource, and initiate a GET request to retrieve a representation of a resource. Conceptually, there is one endpoint in the form of a Customer resource in these cases, and the operations we can carry out upon it are baked into the HTTP protocol.
Implementing Asynchronous Event-Based Collaboration
There are two main parts we need to consider here: a way for our microservices to emit events, and a way for our consumers to find out those events have happened. Traditionally, message brokers like RabbitMQ try to handle both problems. Producers use an API to publish an event to the broker. The broker handles subscriptions, allowing consumers to be informed when an event arrives. These brokers can even handle the state of consumers, for example by helping keep track of what messages they have seen before. These systems are normally designed to be scalable and resilient, but that doesn’t come for free. It can add complexity to the development process, because it is another system you may need to run to develop and test your services. Additional machines and expertise may also be required to keep this infrastructure up and running. But once it does, it can be an incredibly effective way to implement loosely coupled, event-driven architectures. In general, I’m a fan.
Do be wary, though, about the world of middleware, of which the message broker is just a small part. Queues in and of themselves are perfectly sensible, useful things. However, vendors tend to want to package lots of software with them, which can lead to more and more smarts being pushed into the middleware, as evidenced by things like the Enterprise Service Bus. Make sure you know what you’re getting: keep your middleware dumb, and keep the smarts in the endpoints.
Summary
We’ve looked at a number of different options around integration, and I’ve shared my thoughts on what choices are most likely to ensure our microservices remain as decoupled as possible from their other collaborators:
- Avoid database integration at all costs.
- Understand the trade-offs between REST and RPC, but strongly consider REST as a good starting point for request/response integration.
- Prefer choreography over orchestration.
- Avoid breaking changes and the need to version by understanding Postel’s Law and using tolerant readers.
- Think of user interfaces as compositional layers.
Splitting the Monolith
Deciding that you’d like a monolithic service or application to be smaller is a good start. But I would strongly advise you to chip away at these systems. An incremental approach will help you learn about microservices as you go, and will also limit the impact of getting something wrong (and you will get things wrong!). Think of our monolith as a block of marble. We could blow the whole thing up, but that rarely ends well. It makes much more sense to just chip away at it incrementally.
So if we are going to break apart the monolith a piece at a time, where should we start? We have our seams now, but which one should we pull out first? It’s best to think about where you are going to get the most benefit from some part of your codebase being separated, rather than just splitting things for the sake of it. Let’s consider some drivers that might help guide our chisel.
Pace of Change
Perhaps we know that we have a load of changes coming up soon in how we manage inventory. If we split out the warehouse seam as a service now, we could change that service faster, as it is a separate autonomous unit.
Team Structure
MusicCorp’s delivery team is actually split across two geographical regions. One team is in London, the other in Hawaii (some people have it easy!). It would be great if we could split out the code that the Hawaii team works on the most, so it can take full ownership. We’ll explore this idea further in Chapter 10.
Security
MusicCorp has had a security audit, and has decided to tighten up its protection of sensitive information. Currently, all of this is handled by the finance-related code. If we split this service out, we can provide additional protections to this individual service in terms of monitoring, protection of data at transit, and protection of data at rest—ideas we’ll look at in more detail in Chapter 9.
Technology
The team looking after our recommendation system has been spiking out some new algorithms using a logic programming library in the language Clojure. The team thinks this could benefit our customers by improving what we offer them. If we could split out the recommendation code into a separate service, it would be easy to consider building an alternative implementation that we could test against.
Deployment
Continuous integration (CI) has been around for a number of years at this point. It’s worth spending a bit of time going over the basics, however, as especially when we think about the mapping between microservices, builds, and version control repositories, there are some different options to consider. With CI, the core goal is to keep everyone in sync with each other, which we achieve by making sure that newly checked-in code properly integrates with existing code. To do this, a CI server detects that the code has been committed, checks it out, and carries out some verification like making sure the code compiles and that tests pass. As part of this process, we often create artifact(s) that are used for further validation, such as deploying a running service to run tests against it. Ideally, we want to build these artifacts once and once only, and use them for all deployments of that version of the code. This is in order to avoid doing the same thing over and over again, and so that we can confirm that the artifact we deployed is the one we tested. To enable these artifacts to be reused, we place them in a repository of some sort, either provided by the CI tool itself or on a separate system.
We’ve covered a lot of ground here, so a recap is in order. First, focus on maintaining the ability to release one service independently from another, and make sure that whatever technology you select supports this. I greatly prefer having a single repository per microservice, but am firmer still that you need one CI build per microservice if you want to deploy them separately.
Next, if possible, move to a single-service per host/container. Look at alternative technologies like LXC or Docker to make managing the moving parts cheaper and easier, but understand that whatever technology you adopt, a culture of automation is key to managing everything. Automate everything, and if the technology you have doesn’t allow this, get some new technology! Being able to use a platform like AWS will give you huge benefits when it comes to automation.
Make sure you understand the impact your deployment choices have on developers, and make sure they feel the love too. Creating tools that let you self-service-deploy any given service into a number of different environments is really important, and will help developers, testers, and operations people alike.
Testing
Unit Tests
These are tests that typically test a single function or method call. The tests generated as a side effect of test-driven design (TDD) will fall into this category, as do the sorts of tests generated by techniques such as property-based testing. We’re not launching services here, and are limiting the use of external files or network connections. In general, you want a large number of these sorts of tests. Done right, they are very, very fast, and on modern hardware you could expect to run many thousands of these in less than a minute.
Service Tests
Service tests are designed to bypass the user interface and test services directly. In a monolithic application, we might just be testing a collection of classes that provide a service to the UI. For a system comprising a number of services, a service test would test an individual service’s capabilities. The reason we want to test a single service by itself is to improve the isolation of the test to make finding and fixing problems faster. To achieve this isolation, we need to stub out all external collaborators so only the service itself is in scope, as Figure 7-5 shows.
End-to-End Tests
End-to-end tests are tests run against your entire system. Often they will be driving a GUI through a browser, but could easily be mimicking other sorts of user interaction, like uploading a file.
These tests cover a lot of production code. So when they pass, you feel good: you have a high degree of confidence that the code being tested will work in production. But this increased scope comes with downsides, and as we’ll see shortly, they can be very tricky to do well in a microservices context.
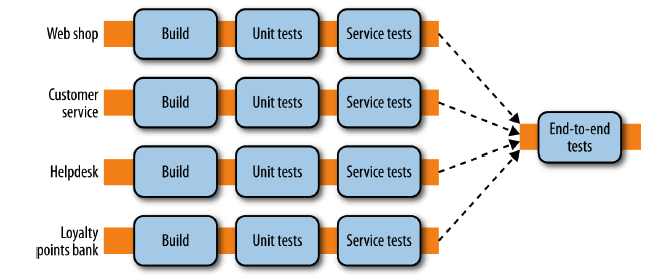
Monitoring
Logs, Logs, and Yet More Logs…
Kibana is an ElasticSearch-backed system for viewing logs, illustrated in Figure 8-4. You can use a query syntax to search through logs, allowing you to do things like restrict time and date ranges or use regular expressions to find matching strings. Kibana can even generate graphs from the logs you send it, allowing you to see at a glance how many errors have been generated over time, for example.
For each service:
- Track inbound response time at a bare minimum. Once you’ve done that, follow with error rates and then start working on application-level metrics.
- Track the health of all downstream responses, at a bare minimum including the response time of downstream calls, and at best tracking error rates. Libraries like Hystrix can help here.
- Standardize on how and where metrics are collected.
- Log into a standard location, in a standard format if possible. Aggregation is a pain if every service uses a different layout!
- Monitor the underlying operating system so you can track down rogue processes and do capacity planning.
For the system:
- Aggregate host-level metrics like CPU together with application-level metrics.
- Ensure your metric storage tool allows for aggregation at a system or service level, and drill down to individual hosts.
- Ensure your metric storage tool allows you to maintain data long enough to understand trends in your system.
- Have a single, queryable tool for aggregating and storing logs.
- Strongly consider standardizing on the use of correlation IDs.
- Understand what requires a call to action, and structure alerting and dashboards accordingly.
- Investigate the possibility of unifying how you aggregate all of your various metrics by seeing if a tool like Suro or Riemann makes sense for you.
Security
Authentication and Authorization
Authentication and authorization are core concepts when it comes to people and things that interact with our system. In the context of security, authentication is the process by which we confirm that a party is who she says she is. For a human, you typically authenticate a user by having her type in her username and password. We assume that only she has access to this information, and therefore that the person entering this information must be her. Other, more complex systems exist as well, of course.
Common Single Sign-On Implementations
A common approach to authentication and authorization is to use some sort of single sign-on (SSO) solution. SAML, which is the reigning implementation in the enterprise space, and OpenID Connect both provide capabilities in this area. More or less they use the same core concepts, although the terminology differs slightly. The terms used here are from SAML. When a principal tries to access a resource (like a web-based interface), she is directed to authenticate with an identity provider. This may ask her to provide a username and password, or might use something more advanced like two-factor authentication. Once the identity provider is satisfied that the principal has been authenticated, it gives information to the service provider, allowing it to decide whether to grant her access to the resource.
Microkernel Architecture
The microkernel architecture pattern (sometimes referred to as the plug-in architecture pattern) is a natural pattern for implementing product-based applications. A product-based application is one that is packaged and made available for download in versions as a typical third-party product. However, many companies also develop and release their internal business applications like software products, complete with versions, release notes, and pluggable features. These are also a natural fit for this pattern. The microkernel architecture pattern allows you to add additional application features as plug-ins to the core application, providing extensibility as well as feature separation and isolation.
Pattern Description
The microkernel architecture pattern consists of two types of architecture components: a core system and plug-in modules. Application logic is divided between independent plug-in modules and the basic core system, providing extensibility, flexibility, and isolation of application features and custom processing logic. Figure 3-1 illustrates the basic microkernel architecture pattern.
The core system of the microkernel architecture pattern traditionally contains only the minimal functionality required to make the system operational. Many operating systems implement the microkernel architecture pattern, hence the origin of this pattern’s name. From a business-application perspective, the core system is often defined as the general business logic sans custom code for special cases, special rules, or complex conditional processing.
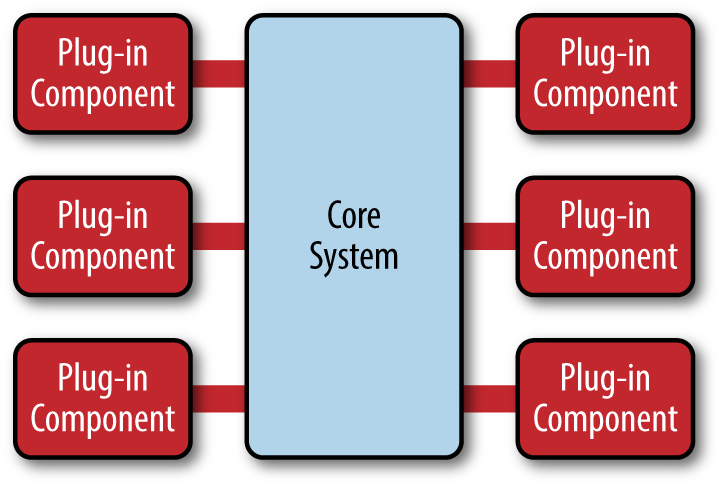
Figure 3-1. Microkernel architecture pattern
The plug-in modules are stand-alone, independent components that contain specialized processing, additional features, and custom code that is meant to enhance or extend the core system to produce additional business capabilities. Generally, plug-in modules should be independent of other plug-in modules, but you can certainly design plug-ins that require other plug-ins to be present. Either way, it is important to keep the communication between plug-ins to a minimum to avoid dependency issues.
The core system needs to know about which plug-in modules are available and how to get to them. One common way of implementing this is through some sort of plug-in registry. This registry contains information about each plug-in module, including things like its name, data contract, and remote access protocol details (depending on how the plug-in is connected to the core system). For example, a plug-in for tax software that flags high-risk tax audit items might have a registry entry that contains the name of the service (AuditChecker), the data contract (input data and output data), and the contract format (XML). It might also contain a WSDL (Web Services Definition Language) if the plug-in is accessed through SOAP.
Plug-in modules can be connected to the core system through a variety of ways, including OSGi (open service gateway initiative), messaging, web services, or even direct point-to-point binding (i.e., object instantiation). The type of connection you use depends on the type of application you are building (small product or large business application) and your specific needs (e.g., single deploy or distributed deployment). The architecture pattern itself does not specify any of these implementation details, only that the plug-in modules must remain independent from one another.
The contracts between the plug-in modules and the core system can range anywhere from standard contracts to custom ones. Custom contracts are typically found in situations where plug-in components are developed by a third party where you have no control over the contract used by the plug-in. In such cases, it is common to create an adapter between the plug-in contact and your standard contract so that the core system doesn’t need specialized code for each plug-in. When creating standard contracts (usually implemented through XML or a Java Map), it is important to remember to create a versioning strategy right from the start.
Pattern Examples
Perhaps the best example of the microkernel architecture is the Eclipse IDE. Downloading the basic Eclipse product provides you little more than a fancy editor. However, once you start adding plug-ins, it becomes a highly customizable and useful product. Internet browsers are another common product example using the microkernel architecture: viewers and other plug-ins add additional capabilities that are not otherwise found in the basic browser (i.e., core system).
The examples are endless for product-based software, but what about large business applications? The microkernel architecture applies to these situations as well. To illustrate this point, let’s use another insurance company example, but this time one involving insurance claims processing.
Claims processing is a very complicated process. Each state has different rules and regulations for what is and isn’t allowed in an insurance claim. For example, some states allow free windshield replacement if your windshield is damaged by a rock, whereas other states do not. This creates an almost infinite set of conditions for a standard claims process.
Not surprisingly, most insurance claims applications leverage large and complex rules engines to handle much of this complexity. However, these rules engines can grow into a complex big ball of mud where changing one rule impacts other rules, or making a simple rule change requires an army of analysts, developers, and testers. Using the microkernel architecture pattern can solve many of these issues.
The stack of folders you see in Figure 3-2 represents the core system for claims processing. It contains the basic business logic required by the insurance company to process a claim, except without any custom processing. Each plug-in module contains the specific rules for that state. In this example, the plug-in modules can be implemented using custom source code or separate rules engine instances. Regardless of the implementation, the key point is that state-specific rules and processing is separate from the core claims system and can be added, removed, and changed with little or no effect on the rest of the core system or other plug-in modules.
Figure 3-2. Microkernel architecture example
Considerations
One great thing about the microkernel architecture pattern is that it can be embedded or used as part of another architecture pattern. For example, if this pattern solves a particular problem you have with a specific volatile area of the application, you might find that you can’t implement the entire architecture using this pattern. In this case, you can embed the microservices architecture pattern in another pattern you are using (e.g., layered architecture). Similarly, the event-processor components described in the previous section on event-driven architecture could be implemented using the microservices architecture pattern.
The microservices architecture pattern provides great support for evolutionary design and incremental development. You can first produce a solid core system, and as the application evolves incrementally, add features and functionality without having to make significant changes to the core system.
For product-based applications, the microkernel architecture pattern should always be your first choice as a starting architecture, particularly for those products where you will be releasing additional features over time and want control over which users get which features. If you find over time that the pattern doesn’t satisfy all of your requirements, you can always refactor your application to another architecture pattern better suited for your specific requirements.
Pattern Analysis
The following table contains a rating and analysis of the common architecture characteristics for the microkernel architecture pattern. The rating for each characteristic is based on the natural tendency for that characteristic as a capability based on a typical implementation of the pattern, as well as what the pattern is generally known for. For a side-by-side comparison of how this pattern relates to other patterns in this report, please refer to Appendix A at the end of this report.
Overall agility
- Rating: High
- Analysis: Overall agility is the ability to respond quickly to a constantly changing environment. Changes can largely be isolated and implemented quickly through loosely coupled plug-in modules. In general, the core system of most microkernel architectures tends to become stable quickly, and as such is fairly robust and requires few changes over time.
Ease of deployment
- Rating: High
- Analysis: Depending on how the pattern is implemented, the plug-in modules can be dynamically added to the core system at runtime (e.g., hot-deployed), minimizing downtime during deployment.
Testability
- Rating: High
- Analysis: Plug-in modules can be tested in isolation and can be easily mocked by the core system to demonstrate or prototype a particular feature with little or no change to the core system.
Performance
- Rating: High
- Analysis: While the microkernel pattern does not naturally lend itself to high-performance applications, in general, most applications built using the microkernel architecture pattern perform well because you can customize and streamline applications to only include those features you need. The JBoss Application Server is a good example of this: with its plug-in architecture, you can trim down the application server to only those features you need, removing expensive non-used features such as remote access, messaging, and caching that consume memory, CPU, and threads and slow down the app server.
Scalability
- Rating: Low
- Analysis: Because most microkernel architecture implementations are product based and are generally smaller in size, they are implemented as single units and hence not highly scalable. Depending on how you implement the plug-in modules, you can sometimes provide scalability at the plug-in feature level, but overall this pattern is not known for producing highly scalable applications.
Ease of development
- Rating: Low
- Analysis: The microkernel architecture requires thoughtful design and contract governance, making it rather complex to implement. Contract versioning, internal plug-in registries, plug-in granularity, and the wide choices available for plug-in connectivity all contribute to the complexity involved with implementing this pattern.
SOA
Message exchange patterns
Introduction to MEPs
There are different ways to exchange data between distributed systems. One fundamental approach to dealing with these differences is to categorize the way chunks of data are exchanged. These chunks of data are called messages. Thus, by categorizing different ways of exchanging messages, we get the so-called message exchange patterns. MEPs define the sequence of messages in a service call or service operation, specifying the order, direction, and cardinality of those messages.
Probably the most important pattern for SOA is request/response (sometimes also called request/reply). In this pattern, the consumer sends a request message to the service provider and waits for the provider to send a response message (see Figure 10-1). The response message might contain requested data and/or a confirmation of successful processing of the request.
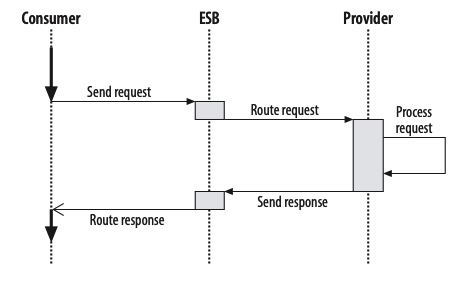
From a consumer’s point of view, such a service call is like a remote procedure call (RPC). That is, the consumer is blocked until the response arrives. You can think of this like a telephone conversation, where you ask a question and wait for the answer before continuing.
Exchanging messages according to this pattern has a big advantage: it makes code pretty simple. A service call is handled like any other function or procedure call. When you need some information or need something to be done, you make your request, wait for the answer or confirmation, and then continue with your work, knowing that the problem has been solved.
The drawback of this pattern is that you cannot do anything else while you are waiting for the response. This typically means either that you need a fast response or that running time doesn’t matter. In practice, a provider processing such a request should usually be available and able to send a response in a reasonable amount of time.
More Complicated MEPs
- Request/Callback
- Publish/Subscribe
Dealing with Different MEP Layers
Message exchange patterns always depend on the characteristics of the transport layer or protocol they use. But one layer above or below, things might look totally different. For example, you can provide asynchronous message exchange patterns on synchronous protocols, and vice versa.
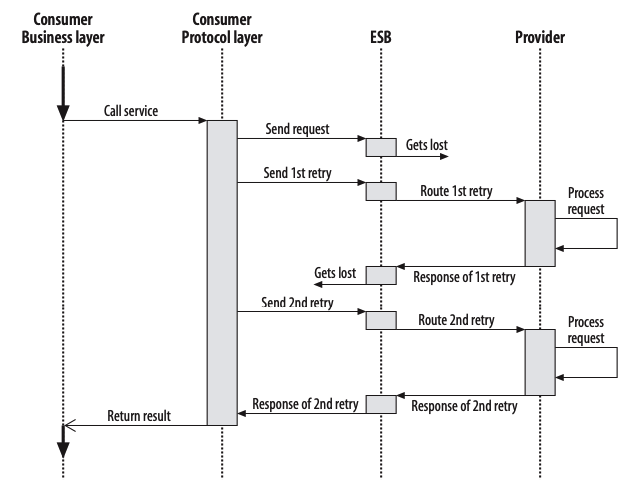
Event-Driven Architecture
There is a lot of discussion at the moment about whether EDA is a special form of SOA, an enhancement of SOA, or something different. For example, some analysts and companies have introduced terms such as “Advanced SOA” or “SOA 2.0” to refer to the combination of EDA and SOA
In my opinion, the most important distinction has to do with the types of events being sent around. Of course, as with services and objects, you can classify events very differently. One interesting difference has to do with whether the events notify consumers about changes with or without including corresponding data:
- If an event just notifies consumers that customer data has changed and needs to be processed, only a small amount of data will be sent around. Data sent with the event will help consumers decide whether the updates are relevant to them—for example, the new general type of the contract or similar information might be included—but in essence these notifications simply indicate that there are updates that need to be processed.
- If an event includes the data to be processed, it will be more coarse-grained. In this case, the conssumer of the event will receive all the information necessary to process this event
- Services use different message exchange patterns (MEPs) that define the order, direction, and cardinality of messages sent around until a specific service operation is done.
- The basic MEPs are request/response and one-way. Also important are the request/ callback (asynchronous or nonblocking request/response) and publish/subscribe patterns, and higher patterns dealing with error handling.
- MEPs are layer-specific. For SOA, the MEPs on the protocol and API layers are important. Events are a special type of one-way messages. They lead to event-driven architecture (EDA), which can be considered a special case or supplementation of SOA.
- One-way messages and events lead to (business) process chains, which is another way of implementing business processes. Instead of orchestrated services, where there is a central controller for the whole process, you get choreographed services, where each service triggers the next step(s) of the business process.
Service lifecycle
Services Under Development
A service is an IT representation of a business functionality. Thus, services are pieces of software. Although the language and format of this software can differ (for example, depending on the implementation platform and/or the classification of the service), it has the usual lifecycle of any software under development, which at its core consists of phases of design, implementation, integration, and bringing into production
FIGURE 11-1 . A typical software lifecycle applies to services
Iterative Service Development
However, there is a special aspect of services to consider: a service is part of a more general business process. Thus, any modifications of a service’s design or implementation might impact other systems. For this reason, we must think about when it is appropriate to modify a service. We’ll begin by looking at the design phase.
The design phase usually produces the specification of the service interface. Ideally this interface includes the semantics and nonfunctional attributes, and it might be part of one or more contracts between the service provider and the (initial) service consumer(s). Therefore, even during the implementation and testing of a service, any changes to its design may impact other systems
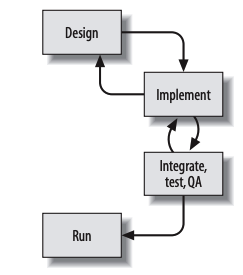
FIGURE 11-2 . A software lifecycle with iterations
You might wonder how often it happens that service designs change during their implementation. Of course, the quality of the design has a lot to do with this. The better the design is, the fewer modifications are typically required. Note, however, that market pressure tends to lead to situations where there is no time for solid design. In addition, even the best designers make mistakes, and in large systems people who know “everything” about a topic almost never exist. So, you should expect that modifications of a service design will be common during its implementation. In my experience, less than 50 percent of designed interfaces remain stable during the implementation phase
Service Identification
Usually, a service is not an end in itself. There should be something that leads to its need and design. In fact, as we have seen already, services are parts of a more general business processes. Thus, a typical scenario that leads to a new service being created is the design of a (new) business process, also known as business process modeling (see Chapter 7 for details).
However, this is not the only approach for identifying new services. Another approach is portfolio management, where a department or company introduces new services because they think it make sense to provide these services (usually expecting that they will be used later). Of course, this approach has its risks, which I discuss in Section 7.5.1.
New services may also be introduced to meet new requirements for existing services. If a modification isn’t backward compatible, a new service (or a new service version) is necessary. A new service version is typically considered to be, technically, a new service (see Section 11.2.1 and Chapter 12 for details).
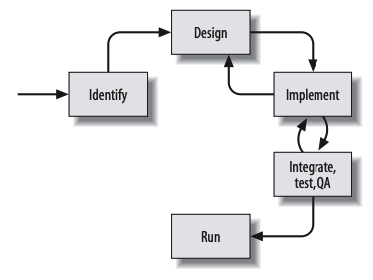
Now, this diagram includes all of the steps taken for a service under development. After identifying that a (new) service is necessary, we design its interface and contract, implement it, and perform the usual tasks to verify its quality (you might call this phase integration, testing, quality assurance, or whatever). Recall that this process is iterative. Tests and integrations might lead to modified implementations, and the design of the service itself may need to be altered.
In rare cases, service development might even lead to experiences that have an impact on service identification. That is, it might turn out that a new service is not useful. However, because this case is relatively rare, I’ve omitted an arrow leading back to service identification.
Services in Production
After a service is developed, it is typically used. That is, the software gets deployed into a running system, performing more or less mission-critical business functionality for the company, enterprise, or universe.
There is an important point to understand here. This is the moment at which the software that implements a service transitions from being software under development to software under maintenance. In general, SOA is a concept that combines new software under development with existing software under maintenance. However, for systems under maintenance different rules apply. For example, modifications become much more critical, especially if the systems have different owners. For this reason, we must also look at how to modify and withdraw services in production
Modifying Services in Production
As soon as a service is in production, it can be used in mission-critical scenarios and business processes. That means whenever you modify such a service (whether its interface or “only” its implementation), you are modifying existing business pro
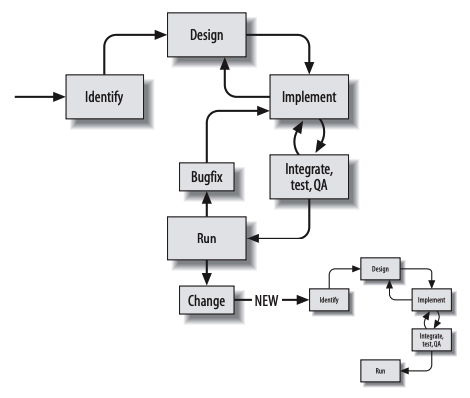
Versioning
There are two common reasons why services (and interfaces in general) have to be modified:
- When implementing new business processes you usually become aware of aspects you didn’t know about or consider at design time, resulting in services (implementations as well as interfaces) needing to be modified.
- New or modified requirements may necessitate modifications of existing services.
Some people argue that with good design, the first case should not happen. One of my customers even deliberately introduced a process that made it difficult to make modifications once a service interface was specified, in an effort to force stability in the designs.
However, in practice, interfaces are no more stable than any other code. One reason is that people make mistakes (which you should be able to correct when you recognize them). In addition, these days we don’t often have enough time for good designs. Finally, reality is always different from what we anticipate.
When you implement business processes, you learn. According to your new insights, you may decide to modify even interfaces. Otherwise, inappropriate or bad designs would remain in your system for years
- SOA requires a smooth migration strategy for new service versions.
- The best approach is to treat each modification of a service (in production) technically as a new service.
- If you have typed APIs for services, versioning of service types is also recommended (although there are alternatives).
- To avoid an explosion of versions, you have to introduce processes to deprecate and remove old service versions. This is one reason why it’s useful to be able to monitor service calls.
- To become independent from versioning aspects of called services, service consumers usually should have a thin layer that maps external data types into internal data types.
- Service modifications should never affect anyone other than the service provider and consumer(s).
- To be “forward compatible,” you might provide an attribute for upcoming call constraints. This enables consumers to signal special needs at runtime, without having to modify service signatures. However, be cautious about making everything generic, because this might introduce a lot of complexity and hidden dependencies.
Performance
- For services, performance (especially running time) is an issue.
- Switching from proprietary remote data access to services can have a significant impact on running times.
- There can be a tradeoff between reusability and performance.
- Performance can have an impact on service granularity, in both directions: services tend to become more coarse-grained if the overhead of multiple service calls is too high, and more fine-grained if the overhead of processing unnecessary data is too high. In addition, coarse granularity should be considered to have reached its limit when services become generic silver bullets.
- Call constraints might help to (temporarily) implement special service behavior without breaking the service’s formal interface (signature).
- Nonfunctional attributes (SLAs) are part of a service contract. For this reason, additional attributes that cause runtime penalties can break the backward compatibility of a service.
- Performance aspects can break business process and system designs, which introduces some risks when using business-process-modeling standards like BPEL that ignore nonfunctional attributes.
Security
When talking about security in distributed systems many different aspects come into play, and as usual, there are many different ways to categorize them. Generally speaking, the following categories are key:
- Authentication
Authentication has to do with verifying an identity. An identity may be a user, a physical device, or a foreign service requestor. Regarding SOA, this means finding out who is calling the service.
- Authorization
Authorization has to do with determining what an identity is allowed to do. Regarding SOA, this means checking whether the caller is allowed to call the service and/or see the result.
- Confidentiality
Whether data remains confidential while in transit or in storage is another key aspect of security. Regarding services, this means ensuring that no one besides the service caller can see service data while it is being transferred between the provider and the consumer.
- Integrity
The key here is guaranteeing that data can’t get manipulated or counterfeited, such that either the data is simply wrong or, even worse, authentication and authorization credentials are faked so that someone can get access to data she is not supposed to see.
- Availability
It is possible to attack (“flood”) a system in such a way that, while data is not lost or corrupted, the system simply becomes inoperable. A typical form of flooding is a “denial of service” (DoS) attack.
- Accounting
The key here is to keep track of the consumption of resources. Regarding SOA, this means tracking service calls for management, planning, billing, or other purposes.
- Auditing
The key here is to evaluate a security concept and its application, with the aim of improving its reliability. Auditing might involve recording all security-relevant information, so that you can detect or analyze security holes and attacks. So, it also includes monitoring, logging, and tracing of all security-relevant data flow. In addition, auditing may be a functional component: when services are manipulating data, this manipulation has to be “audited” (e.g., for legal reasons).
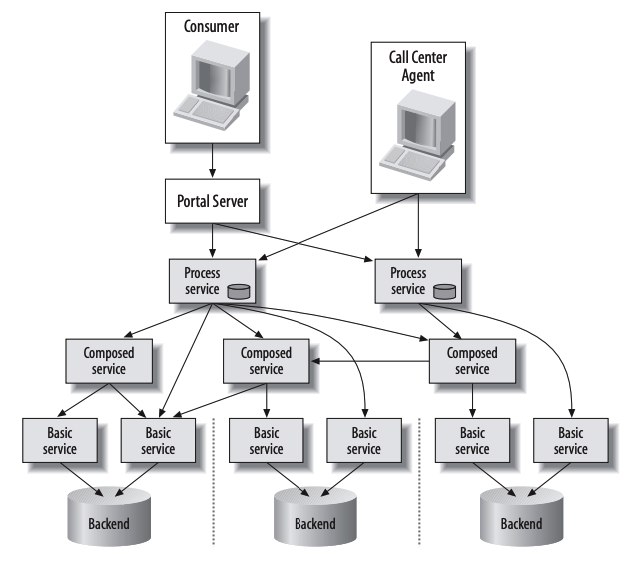
These many layers lead to two important problems:
- It is not clear which system authenticates and authorizes a user.
- Confidentiality must be assured across not one but multiple connections and nodes in between.
In practice, security is very often neglected, for several reasons:
- Security requires effort.
- It is impossible to achieve absolute security (except by disconnecting distributed systems).
- You might assume that the usual security mechanisms for the Internet (firewalls and special protocols such as SSL) are enough.
- You might assume that SOA infrastructures usually provide enough security.
- It is not clear whether security is an issue for the infrastructure team or the business teams.
- Transport-layer security
Here, you use the underlying protocol of your infrastructure to introduce security. A typical example is encryption of Web Services calls via SSL (that is, using the HTTPS protocol instead of HTTP). While this is typically easy and cheap, the problem is that it only helps when data gets transferred from system to system (or node to node). That is, this is a point-to-point encryption instead of an end-to-end encryption. Inside the nodes and between different layers, the data is still readable.
- Message-layer security
Here, you introduce security within the actual messages being sent. That is, you use the protocol of your infrastructure in such a way that nobody is able to read the messages or modify them without being detected. For this approach, you have to define some special constraints in the format of your messages so that all endpoints are able to communicate with each other. While the sender of a message might encrypt or certify all of the data or parts of it, the receiver decrypts the message or verifies the certificate. A typical example is encryption of Web Services with additional attributes defined by standards such as WS-Security.
- In SOA, the usual security aspects and techniques of distributed systems apply,
together with some supplementary threads:
- SOA forces high interoperability, which lowers default security.
- SOA has to deal with the heterogeneous security concepts of existing systems.
- Distributed processes transfer data over multiple services, so point-to-point solutions are not enough for end-to-end security.
- Multiclient capabilities force runtime security checks.
- You must define and implement a strategic security approach that covers infrastructure, architecture, and applications. The best approach is to introduce security as a service.
- Security influences performance, and it might force stateless services to be able to deal with state.
- XML and Web Services might introduce special security problems, such as the danger of XML bombs and XPATH injections.
- Keep security in mind from the beginning (which does not mean that you need to try to deal with all aspects of security immediately).
GoF
Builder
Builder is a creational design pattern that lets you construct complex objects step by step. The pattern allows you to produce different types and representations of an object using the same construction code.
Problem
Imagine a complex object that requires laborious, step-by-step initialization of many fields and nested objects. Such initialization code is usually buried inside a monstrous constructor with lots of parameters. Or even worse: scattered all over the client code.
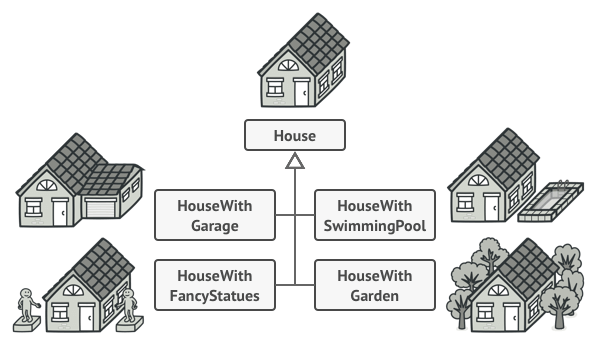
You might make the program too complex by creating a subclass for every possible configuration of an object.
For example, let’s think about how to create a House object. To build a simple house, you need to construct four walls and a floor, install a door, fit a pair of windows, and build a roof. But what if you want a bigger, brighter house, with a backyard and other goodies (like a heating system, plumbing, and electrical wiring)?
The simplest solution is to extend the base House class and create a set of subclasses to cover all combinations of the parameters. But eventually you’ll end up with a considerable number of subclasses. Any new parameter, such as the porch style, will require growing this hierarchy even more.
There’s another approach that doesn’t involve breeding subclasses. You can create a giant constructor right in the base House class with all possible parameters that control the house object. While this approach indeed eliminates the need for subclasses, it creates another problem.
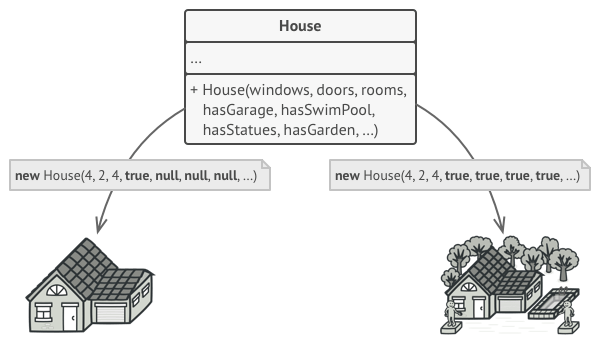
The constructor with lots of parameters has its downside: not all the parameters are needed at all times.
In most cases most of the parameters will be unused, making the constructor calls pretty ugly. For instance, only a fraction of houses have swimming pools, so the parameters related to swimming pools will be useless nine times out of ten.
Solution
The Builder pattern suggests that you extract the object construction code out of its own class and move it to separate objects called builders.
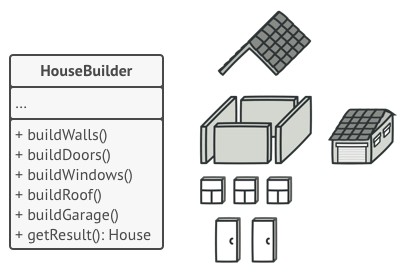
The Builder pattern lets you construct complex objects step by step. The Builder doesn’t allow other objects to access the product while it’s being built.
The pattern organizes object construction into a set of steps (buildWalls, buildDoor, etc.). To create an object, you execute a series of these steps on a builder object. The important part is that you don’t need to call all of the steps. You can call only those steps that are necessary for producing a particular configuration of an object.
Some of the construction steps might require different implementation when you need to build various representations of the product. For example, walls of a cabin may be built of wood, but the castle walls must be built with stone.
In this case, you can create several different builder classes that implement the same set of building steps, but in a different manner. Then you can use these builders in the construction process (i.e., an ordered set of calls to the building steps) to produce different kinds of objects.

Different builders execute the same task in various ways.
For example, imagine a builder that builds everything from wood and glass, a second one that builds everything with stone and iron and a third one that uses gold and diamonds. By calling the same set of steps, you get a regular house from the first builder, a small castle from the second and a palace from the third. However, this would only work if the client code that calls the building steps is able to interact with builders using a common interface.
Director
You can go further and extract a series of calls to the builder steps you use to construct a product into a separate class called director. The director class defines the order in which to execute the building steps, while the builder provides the implementation for those steps.

The director knows which building steps to execute to get a working product.
Having a director class in your program isn’t strictly necessary. You can always call the building steps in a specific order directly from the client code. However, the director class might be a good place to put various construction routines so you can reuse them across your program.
In addition, the director class completely hides the details of product construction from the client code. The client only needs to associate a builder with a director, launch the construction with the director, and get the result from the builder.
Pseudocode
This example of the Builder pattern illustrates how you can reuse the same object construction code when building different types of products, such as cars, and create the corresponding manuals for them.
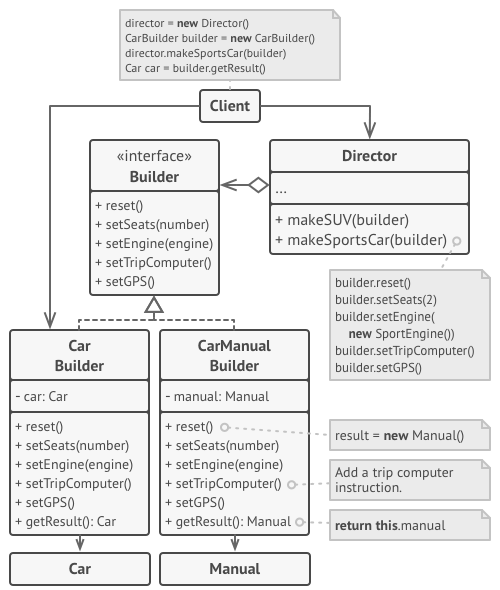
The example of step-by-step construction of cars and the user guides that fit those car models.
A car is a complex object that can be constructed in a hundred different ways. Instead of bloating the Car class with a huge constructor, we extracted the car assembly code into a separate car builder class. This class has a set of methods for configuring various parts of a car.
If the client code needs to assemble a special, fine-tuned model of a car, it can work with the builder directly. On the other hand, the client can delegate the assembly to the director class, which knows how to use a builder to construct several of the most popular models of cars.
You might be shocked, but every car needs a manual (seriously, who reads them?). The manual describes every feature of the car, so the details in the manuals vary across the different models. That’s why it makes sense to reuse an existing construction process for both real cars and their respective manuals. Of course, building a manual isn’t the same as building a car, and that’s why we must provide another builder class that specializes in composing manuals. This class implements the same building methods as its car-building sibling, but instead of crafting car parts, it describes them. By passing these builders to the same director object, we can construct either a car or a manual.
Applicability
- Use the Builder pattern to get rid of a “telescopic constructor”.
Say you have a constructor with ten optional parameters. Calling such a beast is very inconvenient; therefore, you overload the constructor and create several shorter versions with fewer parameters. These constructors still refer to the main one, passing some default values into any omitted parameters.
class Pizza {
Pizza(int size) { ... }
Pizza(int size, boolean cheese) { ... }
Pizza(int size, boolean cheese, boolean pepperoni) { ... }
// ...
Creating such a monster is only possible in languages that support method overloading, such as C# or Java.
The Builder pattern lets you build objects step by step, using only those steps that you really need. After implementing the pattern, you don’t have to cram dozens of parameters into your constructors anymore.
Use the Builder pattern when you want your code to be able to create different representations of some product (for example, stone and wooden houses). The Builder pattern can be applied when construction of various representations of the product involves similar steps that differ only in the details. The base builder interface defines all possible construction steps, and concrete builders implement these steps to construct particular representations of the product. Meanwhile, the director class guides the order of construction.
Use the Builder to construct Composite trees or other complex objects. The Builder pattern lets you construct products step-by-step. You could defer execution of some steps without breaking the final product. You can even call steps recursively, which comes in handy when you need to build an object tree. A builder doesn’t expose the unfinished product while running construction steps. This prevents the client code from fetching an incomplete result.
How to Implement
Make sure that you can clearly define the common construction steps for building all available product representations. Otherwise, you won’t be able to proceed with implementing the pattern.
Declare these steps in the base builder interface.
Create a concrete builder class for each of the product representations and implement their construction steps.
Don’t forget about implementing a method for fetching the result of the construction. The reason why this method can’t be declared inside the builder interface is that various builders may construct products that don’t have a common interface. Therefore, you don’t know what would be the return type for such a method. However, if you’re dealing with products from a single hierarchy, the fetching method can be safely added to the base interface.
Think about creating a director class. It may encapsulate various ways to construct a product using the same builder object.
The client code creates both the builder and the director objects. Before construction starts, the client must pass a builder object to the director. Usually, the client does this only once, via parameters of the director’s constructor. The director uses the builder object in all further construction. There’s an alternative approach, where the builder is passed directly to the construction method of the director.
The construction result can be obtained directly from the director only if all products follow the same interface. Otherwise, the client should fetch the result from the builder.
Pros and Cons
- (+) You can construct objects step-by-step, defer construction steps or run steps recursively.
- (+) You can reuse the same construction code when building various representations of products.
- (+) Single Responsibility Principle. You can isolate complex construction code from the business logic of the product.
- (-) The overall complexity of the code increases since the pattern requires creating multiple new classes.
Bridge
Bridge is a structural design pattern that lets you split a large class or a set of closely related classes into two separate hierarchies—abstraction and implementation—which can be developed independently of each other.
Problem
Abstraction? Implementation? Sound scary? Stay calm and let’s consider a simple example.
Say you have a geometric Shape class with a pair of subclasses: Circle and Square. You want to extend this class hierarchy to incorporate colors, so you plan to create Red and Blue shape subclasses. However, since you already have two subclasses, you’ll need to create four class combinations such as BlueCircle and RedSquare.
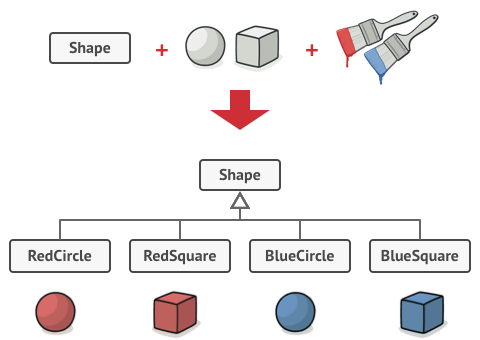
Number of class combinations grows in geometric progression.
Adding new shape types and colors to the hierarchy will grow it exponentially. For example, to add a triangle shape you’d need to introduce two subclasses, one for each color. And after that, adding a new color would require creating three subclasses, one for each shape type. The further we go, the worse it becomes.
Solution
This problem occurs because we’re trying to extend the shape classes in two independent dimensions: by form and by color. That’s a very common issue with class inheritance.
The Bridge pattern attempts to solve this problem by switching from inheritance to the object composition. What this means is that you extract one of the dimensions into a separate class hierarchy, so that the original classes will reference an object of the new hierarchy, instead of having all of its state and behaviors within one class.

You can prevent the explosion of a class hierarchy by transforming it into several related hierarchies.
Following this approach, we can extract the color-related code into its own class with two subclasses: Red and Blue. The Shape class then gets a reference field pointing to one of the color objects. Now the shape can delegate any color-related work to the linked color object. That reference will act as a bridge between the Shape and Color classes. From now on, adding new colors won’t require changing the shape hierarchy, and vice versa.
Abstraction and Implementation
The GoF book introduces the terms Abstraction and Implementation as part of the Bridge definition. In my opinion, the terms sound too academic and make the pattern seem more complicated than it really is. Having read the simple example with shapes and colors, let’s decipher the meaning behind the GoF book’s scary words.
Abstraction (also called interface) is a high-level control layer for some entity. This layer isn’t supposed to do any real work on its own. It should delegate the work to the implementation layer (also called platform).
Note that we’re not talking about interfaces or abstract classes from your programming language. These aren’t the same things.
When talking about real applications, the abstraction can be represented by a graphical user interface (GUI), and the implementation could be the underlying operating system code (API) which the GUI layer calls in response to user interactions.
Generally speaking, you can extend such an app in two independent directions:
- Have several different GUIs (for instance, tailored for regular customers or admins).
- Support several different APIs (for example, to be able to launch the app under Windows, Linux, and MacOS).
In a worst-case scenario, this app might look like a giant spaghetti bowl, where hundreds of conditionals connect different types of GUI with various APIs all over the code.
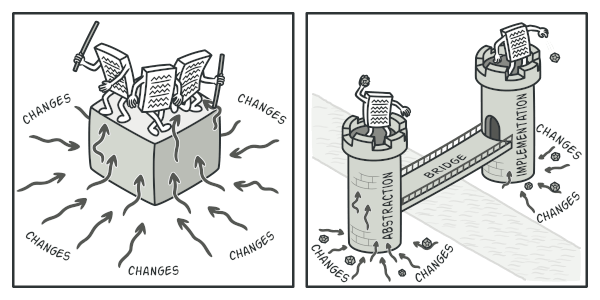
Making even a simple change to a monolithic codebase is pretty hard because you must understand the entire thing very well. Making changes to smaller, well-defined modules is much easier.
You can bring order to this chaos by extracting the code related to specific interface-platform combinations into separate classes. However, soon you’ll discover that there are lots of these classes. The class hierarchy will grow exponentially because adding a new GUI or supporting a different API would require creating more and more classes.
Let’s try to solve this issue with the Bridge pattern. It suggests that we divide the classes into two hierarchies:
- Abstraction: the GUI layer of the app.
- Implementation: the operating systems’ APIs.
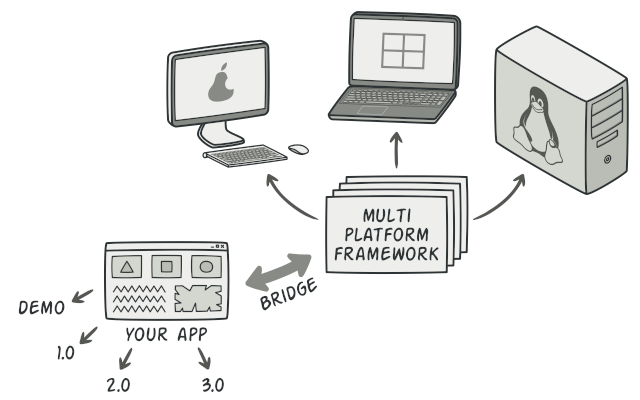
One of the ways to structure a cross-platform application.
The abstraction object controls the appearance of the app, delegating the actual work to the linked implementation object. Different implementations are interchangeable as long as they follow a common interface, enabling the same GUI to work under Windows and Linux.
As a result, you can change the GUI classes without touching the API-related classes. Moreover, adding support for another operating system only requires creating a subclass in the implementation hierarchy.
Pseudocode
This example illustrates how the Bridge pattern can help divide the monolithic code of an app that manages devices and their remote controls. The Device classes act as the implementation, whereas the Remotes act as the abstraction.
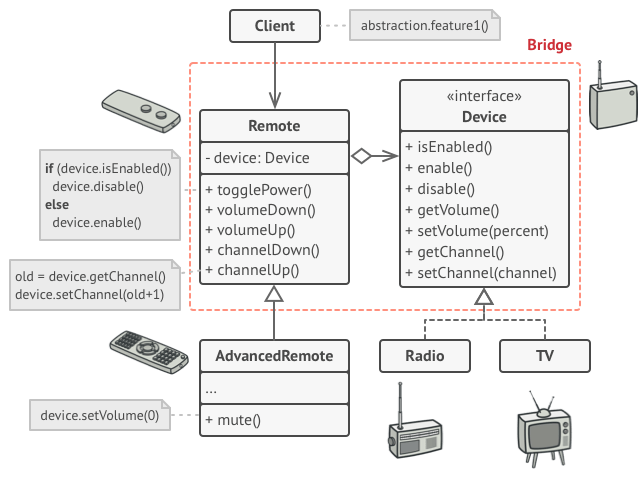
The original class hierarchy is divided into two parts: devices and remote controls.
The base remote control class declares a reference field that links it with a device object. All remotes work with the devices via the general device interface, which lets the same remote support multiple device types.
You can develop the remote control classes independently from the device classes. All that’s needed is to create a new remote subclass. For example, a basic remote control might only have two buttons, but you could extend it with additional features, such as an extra battery or a touchscreen.
Applicability
- Use the Bridge pattern when you want to divide and organize a monolithic class that has several variants of some functionality (for example, if the class can work with various database servers). The bigger a class becomes, the harder it is to figure out how it works, and the longer it takes to make a change. The changes made to one of the variations of functionality may require making changes across the whole class, which often results in making errors or not addressing some critical side effects.
The Bridge pattern lets you split the monolithic class into several class hierarchies. After this, you can change the classes in each hierarchy independently of the classes in the others. This approach simplifies code maintenance and minimizes the risk of breaking existing code.
Use the pattern when you need to extend a class in several orthogonal (independent) dimensions. The Bridge suggests that you extract a separate class hierarchy for each of the dimensions. The original class delegates the related work to the objects belonging to those hierarchies instead of doing everything on its own.
Use the Bridge if you need to be able to switch implementations at runtime. Although it’s optional, the Bridge pattern lets you replace the implementation object inside the abstraction. It’s as easy as assigning a new value to a field. By the way, this last item is the main reason why so many people confuse the Bridge with the Strategy pattern. Remember that a pattern is more than just a certain way to structure your classes. It may also communicate intent and a problem being addressed.
How to Implement
Identify the orthogonal dimensions in your classes. These independent concepts could be: abstraction/platform, domain/infrastructure, front-end/back-end, or interface/implementation.
See what operations the client needs and define them in the base abstraction class.
Determine the operations available on all platforms. Declare the ones that the abstraction needs in the general implementation interface.
For all platforms in your domain create concrete implementation classes, but make sure they all follow the implementation interface.
Inside the abstraction class, add a reference field for the implementation type. The abstraction delegates most of the work to the implementation object that’s referenced in that field.
If you have several variants of high-level logic, create refined abstractions for each variant by extending the base abstraction class.
The client code should pass an implementation object to the abstraction’s constructor to associate one with the other. After that, the client can forget about the implementation and work only with the abstraction object.
Pros and Cons
- (+) You can create platform-independent classes and apps.
- (+) The client code works with high-level abstractions. It isn’t exposed to the platform details.
- (+) Open/Closed Principle. You can introduce new abstractions and implementations independently from each other.
- (+) Single Responsibility Principle. You can focus on high-level logic in the abstraction and on platform details in the implementation.
- (-) You might make the code more complicated by applying the pattern to a highly cohesive class.
Facade
Facade is a structural design pattern that provides a simplified interface to a library, a framework, or any other complex set of classes.
Problem
Imagine that you must make your code work with a broad set of objects that belong to a sophisticated library or framework. Ordinarily, you’d need to initialize all of those objects, keep track of dependencies, execute methods in the correct order, and so on.
As a result, the business logic of your classes would become tightly coupled to the implementation details of 3rd-party classes, making it hard to comprehend and maintain.
Solution
A facade is a class that provides a simple interface to a complex subsystem which contains lots of moving parts. A facade might provide limited functionality in comparison to working with the subsystem directly. However, it includes only those features that clients really care about.
Having a facade is handy when you need to integrate your app with a sophisticated library that has dozens of features, but you just need a tiny bit of its functionality.
For instance, an app that uploads short funny videos with cats to social media could potentially use a professional video conversion library. However, all that it really needs is a class with the single method encode(filename, format). After creating such a class and connecting it with the video conversion library, you’ll have your first facade.
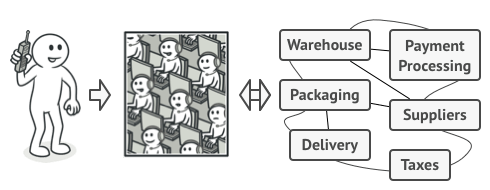
Instead of making your code work with dozens of the framework classes directly, you create a facade class which encapsulates that functionality and hides it from the rest of the code. This structure also helps you to minimize the effort of upgrading to future versions of the framework or replacing it with another one. The only thing you’d need to change in your app would be the implementation of the facade’s methods.
Real-World Analogy
Applicability
Use the Facade pattern when you need to have a limited but straightforward interface to a complex subsystem.
Often, subsystems get more complex over time. Even applying design patterns typically leads to creating more classes. A subsystem may become more flexible and easier to reuse in various contexts, but the amount of configuration and boilerplate code it demands from a client grows ever larger. The Facade attempts to fix this problem by providing a shortcut to the most-used features of the subsystem which fit most client requirements.
Use the Facade when you want to structure a subsystem into layers.
Create facades to define entry points to each level of a subsystem. You can reduce coupling between multiple subsystems by requiring them to communicate only through facades.
How to Implement
Check whether it’s possible to provide a simpler interface than what an existing subsystem already provides. You’re on the right track if this interface makes the client code independent from many of the subsystem’s classes.
Declare and implement this interface in a new facade class. The facade should redirect the calls from the client code to appropriate objects of the subsystem. The facade should be responsible for initializing the subsystem and managing its further life cycle unless the client code already does this.
To get the full benefit from the pattern, make all the client code communicate with the subsystem only via the facade. Now the client code is protected from any changes in the subsystem code. For example, when a subsystem gets upgraded to a new version, you will only need to modify the code in the facade.
If the facade becomes too big, consider extracting part of its behavior to a new, refined facade class.
Pros and `cons
- (+) You can isolate your code from the complexity of a subsystem.
- (-) A facade can become a god object coupled to all classes of an app.
Flyweight
Flyweight is a structural design pattern that lets you fit more objects into the available amount of RAM by sharing common parts of state between multiple objects instead of keeping all of the data in each object.
Problem Problem
To have some fun after long working hours, you decided to create a simple video game: players would be moving around a map and shooting each other. You chose to implement a realistic particle system and make it a distinctive feature of the game. Vast quantities of bullets, missiles, and shrapnel from explosions should fly all over the map and deliver a thrilling experience to the player.
Upon its completion, you pushed the last commit, built the game and sent it to your friend for a test drive. Although the game was running flawlessly on your machine, your friend wasn’t able to play for long. On his computer, the game kept crashing after a few minutes of gameplay. After spending several hours digging through debug logs, you discovered that the game crashed because of an insufficient amount of RAM. It turned out that your friend’s rig was much less powerful than your own computer, and that’s why the problem emerged so quickly on his machine.
The actual problem was related to your particle system. Each particle, such as a bullet, a missile or a piece of shrapnel was represented by a separate object containing plenty of data. At some point, when the carnage on a player’s screen reached its climax, newly created particles no longer fit into the remaining RAM, so the program crashed.
Solution
On closer inspection of the Particle class, you may notice that the color and sprite fields consume a lot more memory than other fields. What’s worse is that these two fields store almost identical data across all particles. For example, all bullets have the same color and sprite.
Other parts of a particle’s state, such as coordinates, movement vector and speed, are unique to each particle. After all, the values of these fields change over time. This data represents the always changing context in which the particle exists, while the color and sprite remain constant for each particle.
This constant data of an object is usually called the intrinsic state. It lives within the object; other objects can only read it, not change it. The rest of the object’s state, often altered “from the outside” by other objects, is called the extrinsic state.
The Flyweight pattern suggests that you stop storing the extrinsic state inside the object. Instead, you should pass this state to specific methods which rely on it. Only the intrinsic state stays within the object, letting you reuse it in different contexts. As a result, you’d need fewer of these objects since they only differ in the intrinsic state, which has much fewer variations than the extrinsic.
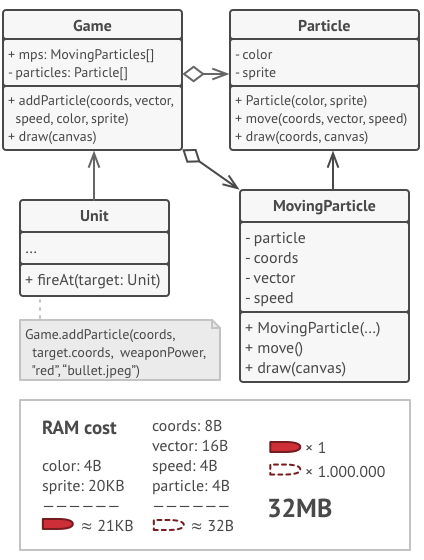
Let’s return to our game. Assuming that we had extracted the extrinsic state from our particle class, only three different objects would suffice to represent all particles in the game: a bullet, a missile, and a piece of shrapnel. As you’ve probably guessed by now, an object that only stores the intrinsic state is called a flyweight.
Extrinsic state storage
Where does the extrinsic state move to? Some class should still store it, right? In most cases, it gets moved to the container object, which aggregates objects before we apply the pattern.
In our case, that’s the main Game object that stores all particles in the particles field. To move the extrinsic state into this class, you need to create several array fields for storing coordinates, vectors, and speed of each individual particle. But that’s not all. You need another array for storing references to a specific flyweight that represents a particle. These arrays must be in sync so that you can access all data of a particle using the same index.
A more elegant solution is to create a separate context class that would store the extrinsic state along with reference to the flyweight object. This approach would require having just a single array in the container class.
Wait a second! Won’t we need to have as many of these contextual objects as we had at the very beginning? Technically, yes. But the thing is, these objects are much smaller than before. The most memory-consuming fields have been moved to just a few flyweight objects. Now, a thousand small contextual objects can reuse a single heavy flyweight object instead of storing a thousand copies of its data.
Flyweight and immutability
Since the same flyweight object can be used in different contexts, you have to make sure that its state can’t be modified. A flyweight should initialize its state just once, via constructor parameters. It shouldn’t expose any setters or public fields to other objects.
Flyweight factory
For more convenient access to various flyweights, you can create a factory method that manages a pool of existing flyweight objects. The method accepts the intrinsic state of the desired flyweight from a client, looks for an existing flyweight object matching this state, and returns it if it was found. If not, it creates a new flyweight and adds it to the pool.
There are several options where this method could be placed. The most obvious place is a flyweight container. Alternatively, you could create a new factory class. Or you could make the factory method static and put it inside an actual flyweight class.
Applicability
- Use the Flyweight pattern only when your program must support a huge number of objects which barely fit into available RAM.
The benefit of applying the pattern depends heavily on how and where it’s used. It’s most useful when:
- an application needs to spawn a huge number of similar objects
- this drains all available RAM on a target device
- the objects contain duplicate states which can be extracted and shared between multiple objects
How to Implement
- Divide fields of a class that will become a flyweight into two parts:
- the intrinsic state: the fields that contain unchanging data duplicated across many objects
- the extrinsic state: the fields that contain contextual data unique to each object
- Leave the fields that represent the intrinsic state in the class, but make sure they’re immutable. They should take their initial values only inside the constructor.
- Go over methods that use fields of the extrinsic state. For each field used in the method, introduce a new parameter and use it instead of the field.
- Optionally, create a factory class to manage the pool of flyweights. It should check for an existing flyweight before creating a new one. Once the factory is in place, clients must only request flyweights through it. They should describe the desired flyweight by passing its intrinsic state to the factory.
- The client must store or calculate values of the extrinsic state (context) to be able to call methods of flyweight objects. For the sake of convenience, the extrinsic state along with the flyweight-referencing field may be moved to a separate context class.
Pros and Cons
- (+) You can save lots of RAM, assuming your program has tons of similar objects.
- (-) You might be trading RAM over CPU cycles when some of the context data needs to be recalculated each time somebody calls a flyweight method.
- (-) The code becomes much more complicated. New team members will always be wondering why the state of an entity was separated in such a way.
Proxy
Proxy is a structural design pattern that lets you provide a substitute or placeholder for another object. A proxy controls access to the original object, allowing you to perform something either before or after the request gets through to the original object.
Problem
Why would you want to control access to an object? Here is an example: you have a massive object that consumes a vast amount of system resources. You need it from time to time, but not always.

You could implement lazy initialization: create this object only when it’s actually needed. All of the object’s clients would need to execute some deferred initialization code. Unfortunately, this would probably cause a lot of code duplication.
In an ideal world, we’d want to put this code directly into our object’s class, but that isn’t always possible. For instance, the class may be part of a closed 3rd-party library.
Solution
The Proxy pattern suggests that you create a new proxy class with the same interface as an original service object. Then you update your app so that it passes the proxy object to all of the original object’s clients. Upon receiving a request from a client, the proxy creates a real service object and delegates all the work to it.
 The proxy disguises itself as a database object. It can handle lazy initialization and result caching without the client or the real database object even knowing.
The proxy disguises itself as a database object. It can handle lazy initialization and result caching without the client or the real database object even knowing.
But what’s the benefit? If you need to execute something either before or after the primary logic of the class, the proxy lets you do this without changing that class. Since the proxy implements the same interface as the original class, it can be passed to any client that expects a real service object.
Real-World Analogy
 Credit cards can be used for payments just the same as cash.
Credit cards can be used for payments just the same as cash.
A credit card is a proxy for a bank account, which is a proxy for a bundle of cash. Both implement the same interface: they can be used for making a payment. A consumer feels great because there’s no need to carry loads of cash around. A shop owner is also happy since the income from a transaction gets added electronically to the shop’s bank account without the risk of losing the deposit or getting robbed on the way to the bank.
Pseudocode
This example illustrates how the Proxy pattern can help to introduce lazy initialization and caching to a 3rd-party YouTube integration library.
 Caching results of a service with a proxy.
Caching results of a service with a proxy.
The library provides us with the video downloading class. However, it’s very inefficient. If the client application requests the same video multiple times, the library just downloads it over and over, instead of caching and reusing the first downloaded file.
The proxy class implements the same interface as the original downloader and delegates it all the work. However, it keeps track of the downloaded files and returns the cached result when the app requests the same video multiple times.
Applicability
Lazy initialization (virtual proxy). This is when you have a heavyweight service object that wastes system resources by being always up, even though you only need it from time to time. Instead of creating the object when the app launches, you can delay the object’s initialization to a time when it’s really needed.
Access control (protection proxy). This is when you want only specific clients to be able to use the service object; for instance, when your objects are crucial parts of an operating system and clients are various launched applications (including malicious ones). The proxy can pass the request to the service object only if the client’s credentials match some criteria.
Local execution of a remote service (remote proxy). This is when the service object is located on a remote server. In this case, the proxy passes the client request over the network, handling all of the nasty details of working with the network.
Logging requests (logging proxy). This is when you want to keep a history of requests to the service object. The proxy can log each request before passing it to the service.
Caching request results (caching proxy). This is when you need to cache results of client requests and manage the life cycle of this cache, especially if results are quite large. The proxy can implement caching for recurring requests that always yield the same results. The proxy may use the parameters of requests as the cache keys.
Smart reference. This is when you need to be able to dismiss a heavyweight object once there are no clients that use it. The proxy can keep track of clients that obtained a reference to the service object or its results. From time to time, the proxy may go over the clients and check whether they are still active. If the client list gets empty, the proxy might dismiss the service object and free the underlying system resources. The proxy can also track whether the client had modified the service object. Then the unchanged objects may be reused by other clients.
How to Implement
If there’s no pre-existing service interface, create one to make proxy and service objects interchangeable. Extracting the interface from the service class isn’t always possible, because you’d need to change all of the service’s clients to use that interface. Plan B is to make the proxy a subclass of the service class, and this way it’ll inherit the interface of the service.
Create the proxy class. It should have a field for storing a reference to the service. Usually, proxies create and manage the whole life cycle of their servers. In rare occasions, a service is passed to the proxy via a constructor by the client.
Implement the proxy methods according to their purposes. In most cases, after doing some work, the proxy should delegate the work to the service object.
Consider introducing a creation method that decides whether the client gets a proxy or a real service. This can be a simple static method in the proxy class or a full-blown factory method.
Consider implementing lazy initialization for the service object.
Pros and Cons
- (+) You can control the service object without clients knowing about it.
- (+) You can manage the lifecycle of the service object when clients don’t care about it.
- (+) The proxy works even if the service object isn’t ready or is not available.
- (+) Open/Closed Principle. You can introduce new proxies without changing the service or clients.
- (-) The code may become more complicated since you need to introduce a lot of new classes.
- (-) The response from the service might get delayed.
Chain of Responsibility
Chain of Responsibility Pattern
Chain of Responsibility is a behavioral design pattern that lets you pass requests along a chain of handlers. Upon receiving a request, each handler decides either to process the request or to pass it to the next handler in the chain.
Problem
Imagine that you’re working on an online ordering system. You want to restrict access to the system so only authenticated users can create orders. Also, users who have administrative permissions must have full access to all orders.
After a bit of planning, you realized that these checks must be performed sequentially. The application can attempt to authenticate a user to the system whenever it receives a request that contains the user’s credentials. However, if those credentials aren’t correct and authentication fails, there’s no reason to proceed with any other checks.

The request must pass a series of checks before the ordering system itself can handle it.
During the next few months, you implemented several more of those sequential checks.
One of your colleagues suggested that it’s unsafe to pass raw data straight to the ordering system. So you added an extra validation step to sanitize the data in a request.
Later, somebody noticed that the system is vulnerable to brute force password cracking. To negate this, you promptly added a check that filters repeated failed requests coming from the same IP address.
Someone else suggested that you could speed up the system by returning cached results on repeated requests containing the same data. Hence, you added another check which lets the request pass through to the system only if there’s no suitable cached response.
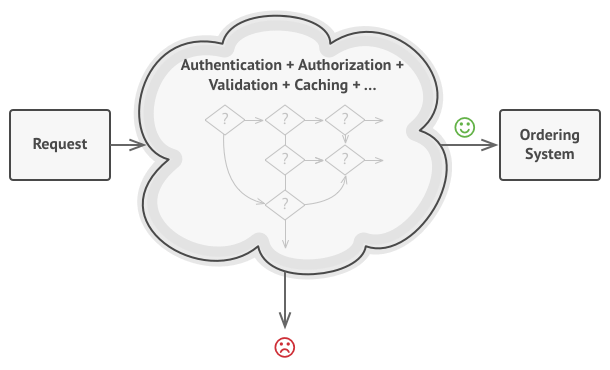
The bigger the code grew, the messier it became.
The code of the checks, which had already looked like a mess, became more and more bloated as you added each new feature. Changing one check sometimes affected the others. Worst of all, when you tried to reuse the checks to protect other components of the system, you had to duplicate some of the code since those components required some of the checks, but not all of them.
The system became very hard to comprehend and expensive to maintain. You struggled with the code for a while, until one day you decided to refactor the whole thing.
Solution
Like many other behavioral design patterns, the Chain of Responsibility relies on transforming particular behaviors into stand-alone objects called handlers. In our case, each check should be extracted to its own class with a single method that performs the check. The request, along with its data, is passed to this method as an argument.
The pattern suggests that you link these handlers into a chain. Each linked handler has a field for storing a reference to the next handler in the chain. In addition to processing a request, handlers pass the request further along the chain. The request travels along the chain until all handlers have had a chance to process it.
Here’s the best part: a handler can decide not to pass the request further down the chain and effectively stop any further processing.
In our example with ordering systems, a handler performs the processing and then decides whether to pass the request further down the chain. Assuming the request contains the right data, all the handlers can execute their primary behavior, whether it’s authentication checks or caching.

Handlers are lined up one by one, forming a chain.
However, there’s a slightly different approach (and it’s a bit more canonical) in which, upon receiving a request, a handler decides whether it can process it. If it can, it doesn’t pass the request any further. So it’s either only one handler that processes the request or none at all. This approach is very common when dealing with events in stacks of elements within a graphical user interface.
For instance, when a user clicks a button, the event propagates through the chain of GUI elements that starts with the button, goes along its containers (like forms or panels), and ends up with the main application window. The event is processed by the first element in the chain that’s capable of handling it. This example is also noteworthy because it shows that a chain can always be extracted from an object tree.
A chain can be formed from a branch of an object tree.
It’s crucial that all handler classes implement the same interface. Each concrete handler should only care about the following one having the execute method. This way you can compose chains at runtime, using various handlers without coupling your code to their concrete classes.
Real-World Analogy

A call to tech support can go through multiple operators.
You’ve just bought and installed a new piece of hardware on your computer. Since you’re a geek, the computer has several operating systems installed. You try to boot all of them to see whether the hardware is supported. Windows detects and enables the hardware automatically. However, your beloved Linux refuses to work with the new hardware. With a small flicker of hope, you decide to call the tech-support phone number written on the box.
The first thing you hear is the robotic voice of the autoresponder. It suggests nine popular solutions to various problems, none of which are relevant to your case. After a while, the robot connects you to a live operator.
Alas, the operator isn’t able to suggest anything specific either. He keeps quoting lengthy excerpts from the manual, refusing to listen to your comments. After hearing the phrase “have you tried turning the computer off and on again?” for the 10th time, you demand to be connected to a proper engineer.
Eventually, the operator passes your call to one of the engineers, who had probably longed for a live human chat for hours as he sat in his lonely server room in the dark basement of some office building. The engineer tells you where to download proper drivers for your new hardware and how to install them on Linux. Finally, the solution! You end the call, bursting with joy.
Applicability
Use the Chain of Responsibility pattern when your program is expected to process different kinds of requests in various ways, but the exact types of requests and their sequences are unknown beforehand. The pattern lets you link several handlers into one chain and, upon receiving a request, “ask” each handler whether it can process it. This way all handlers get a chance to process the request.
Use the pattern when it’s essential to execute several handlers in a particular order. Since you can link the handlers in the chain in any order, all requests will get through the chain exactly as you planned.
Use the CoR pattern when the set of handlers and their order are supposed to change at runtime. If you provide setters for a reference field inside the handler classes, you’ll be able to insert, remove or reorder handlers dynamically.
How to Implement
- Declare the handler interface and describe the signature of a method for handling requests.
Decide how the client will pass the request data into the method. The most flexible way is to convert the request into an object and pass it to the handling method as an argument.
- To eliminate duplicate boilerplate code in concrete handlers, it might be worth creating an abstract base handler class, derived from the handler interface.
This class should have a field for storing a reference to the next handler in the chain. Consider making the class immutable. However, if you plan to modify chains at runtime, you need to define a setter for altering the value of the reference field.
You can also implement the convenient default behavior for the handling method, which is to forward the request to the next object unless there’s none left. Concrete handlers will be able to use this behavior by calling the parent method.
- One by one create concrete handler subclasses and implement their handling methods. Each handler should make two decisions when receiving a request:
- Whether it’ll process the request.
- Whether it’ll pass the request along the chain.
The client may either assemble chains on its own or receive pre-built chains from other objects. In the latter case, you must implement some factory classes to build chains according to the configuration or environment settings.
The client may trigger any handler in the chain, not just the first one. The request will be passed along the chain until some handler refuses to pass it further or until it reaches the end of the chain.
Due to the dynamic nature of the chain, the client should be ready to handle the following scenarios:
- The chain may consist of a single link.
- Some requests may not reach the end of the chain.
- Others may reach the end of the chain unhandled.
Pros and Cons
- (+) You can control the order of request handling.
- (+) Single Responsibility Principle. You can decouple classes that invoke operations from classes that perform operations.
- (+) Open/Closed Principle. You can introduce new handlers into the app without breaking the existing client code.
- (-) Some requests may end up unhandled.
Command
Command is a behavioral design pattern that turns a request into a stand-alone object that contains all information about the request. This transformation lets you parameterize methods with different requests, delay or queue a request’s execution, and support undoable operations.
Problem
Imagine that you’re working on a new text-editor app. Your current task is to create a toolbar with a bunch of buttons for various operations of the editor. You created a very neat Button class that can be used for buttons on the toolbar, as well as for generic buttons in various dialogs.
 All buttons of the app are derived from the same class.
All buttons of the app are derived from the same class.
While all of these buttons look similar, they’re all supposed to do different things. Where would you put the code for the various click handlers of these buttons? The simplest solution is to create tons of subclasses for each place where the button is used. These subclasses would contain the code that would have to be executed on a button click.
 Lots of button subclasses. What can go wrong?
Lots of button subclasses. What can go wrong?
Before long, you realize that this approach is deeply flawed. First, you have an enormous number of subclasses, and that would be okay if you weren’t risking breaking the code in these subclasses each time you modify the base Button class. Put simply, your GUI code has become awkwardly dependent on the volatile code of the business logic.
 Several classes implement the same functionality.
Several classes implement the same functionality.
And here’s the ugliest part. Some operations, such as copying/pasting text, would need to be invoked from multiple places. For example, a user could click a small Copy button on the toolbar, or copy something via the context menu, or just hit Ctrl+C on the keyboard.
Initially, when our app only had the toolbar, it was okay to place the implementation of various operations into the button subclasses. In other words, having the code for copying text inside the CopyButton subclass was fine. But then, when you implement context menus, shortcuts, and other stuff, you have to either duplicate the operation’s code in many classes or make menus dependent on buttons, which is an even worse option.
Solution
Good software design is often based on the principle of separation of concerns, which usually results in breaking an app into layers. The most common example: a layer for the graphical user interface and another layer for the business logic. The GUI layer is responsible for rendering a beautiful picture on the screen, capturing any input and showing results of what the user and the app are doing. However, when it comes to doing something important, like calculating the trajectory of the moon or composing an annual report, the GUI layer delegates the work to the underlying layer of business logic.
In the code it might look like this: a GUI object calls a method of a business logic object, passing it some arguments. This process is usually described as one object sending another a request.
 The GUI objects may access the business logic objects directly.
The GUI objects may access the business logic objects directly.
The Command pattern suggests that GUI objects shouldn’t send these requests directly. Instead, you should extract all of the request details, such as the object being called, the name of the method and the list of arguments into a separate command class with a single method that triggers this request.
Command objects serve as links between various GUI and business logic objects. From now on, the GUI object doesn’t need to know what business logic object will receive the request and how it’ll be processed. The GUI object just triggers the command, which handles all the details.
 Accessing the business logic layer via a command.
Accessing the business logic layer via a command.
The next step is to make your commands implement the same interface. Usually it has just a single execution method that takes no parameters. This interface lets you use various commands with the same request sender, without coupling it to concrete classes of commands. As a bonus, now you can switch command objects linked to the sender, effectively changing the sender’s behavior at runtime.
You might have noticed one missing piece of the puzzle, which is the request parameters. A GUI object might have supplied the business-layer object with some parameters. Since the command execution method doesn’t have any parameters, how would we pass the request details to the receiver? It turns out the command should be either pre-configured with this data, or capable of getting it on its own.
 The GUI objects delegate the work to commands.
The GUI objects delegate the work to commands.
Let’s get back to our text editor. After we apply the Command pattern, we no longer need all those button subclasses to implement various click behaviors. It’s enough to put a single field into the base Button class that stores a reference to a command object and make the button execute that command on a click.
You’ll implement a bunch of command classes for every possible operation and link them with particular buttons, depending on the buttons’ intended behavior.
Other GUI elements, such as menus, shortcuts or entire dialogs, can be implemented in the same way. They’ll be linked to a command which gets executed when a user interacts with the GUI element. As you’ve probably guessed by now, the elements related to the same operations will be linked to the same commands, preventing any code duplication.
As a result, commands become a convenient middle layer that reduces coupling between the GUI and business logic layers. And that’s only a fraction of the benefits that the Command pattern can offer!
Real-World Analogy
 Making an order in a restaurant.
Making an order in a restaurant.
After a long walk through the city, you get to a nice restaurant and sit at the table by the window. A friendly waiter approaches you and quickly takes your order, writing it down on a piece of paper. The waiter goes to the kitchen and sticks the order on the wall. After a while, the order gets to the chef, who reads it and cooks the meal accordingly. The cook places the meal on a tray along with the order. The waiter discovers the tray, checks the order to make sure everything is as you wanted it, and brings everything to your table.
The paper order serves as a command. It remains in a queue until the chef is ready to serve it. The order contains all the relevant information required to cook the meal. It allows the chef to start cooking right away instead of running around clarifying the order details from you directly.
Pseudocode
In this example, the Command pattern helps to track the history of executed operations and makes it possible to revert an operation if needed.
 Undoable operations in a text editor.
Undoable operations in a text editor.
Commands which result in changing the state of the editor (e.g., cutting and pasting) make a backup copy of the editor’s state before executing an operation associated with the command. After a command is executed, it’s placed into the command history (a stack of command objects) along with the backup copy of the editor’s state at that point. Later, if the user needs to revert an operation, the app can take the most recent command from the history, read the associated backup of the editor’s state, and restore it.
The client code (GUI elements, command history, etc.) isn’t coupled to concrete command classes because it works with commands via the command interface. This approach lets you introduce new commands into the app without breaking any existing code.
Applicability
Use the Command pattern when you want to parametrize objects with operations. The Command pattern can turn a specific method call into a stand-alone object. This change opens up a lot of interesting uses: you can pass commands as method arguments, store them inside other objects, switch linked commands at runtime, etc. Here’s an example: you’re developing a GUI component such as a context menu, and you want your users to be able to configure menu items that trigger operations when an end user clicks an item.
Use the Command pattern when you want to queue operations, schedule their execution, or execute them remotely. As with any other object, a command can be serialized, which means converting it to a string that can be easily written to a file or a database. Later, the string can be restored as the initial command object. Thus, you can delay and schedule command execution. But there’s even more! In the same way, you can queue, log or send commands over the network.
Use the Command pattern when you want to implement reversible operations. Although there are many ways to implement undo/redo, the Command pattern is perhaps the most popular of all. To be able to revert operations, you need to implement the history of performed operations. The command history is a stack that contains all executed command objects along with related backups of the application’s state. This method has two drawbacks. First, it isn’t that easy to save an application’s state because some of it can be private. This problem can be mitigated with the Memento pattern. Second, the state backups may consume quite a lot of RAM. Therefore, sometimes you can resort to an alternative implementation: instead of restoring the past state, the command performs the inverse operation. The reverse operation also has a price: it may turn out to be hard or even impossible to implement.
How to Implement
Declare the command interface with a single execution method.
Start extracting requests into concrete command classes that implement the command interface. Each class must have a set of fields for storing the request arguments along with a reference to the actual receiver object. All these values must be initialized via the command’s constructor.
Identify classes that will act as senders. Add the fields for storing commands into these classes. Senders should communicate with their commands only via the command interface. Senders usually don’t create command objects on their own, but rather get them from the client code.
Change the senders so they execute the command instead of sending a request to the receiver directly.
The client should initialize objects in the following order:
- Create receivers.
- Create commands, and associate them with receivers if needed.
- Create senders, and associate them with specific commands.
Pros and Cons
- (+) Single Responsibility Principle. You can decouple classes that invoke operations from classes that perform these operations.
- (+) Open/Closed Principle. You can introduce new commands into the app without breaking existing client code.
- (+) You can implement undo/redo.
- (+) You can implement deferred execution of operations.
- (+) You can assemble a set of simple commands into a complex one.
- (-) The code may become more complicated since you’re introducing a whole new layer between senders and receivers.
Interpreter
Interpreter design pattern is one of the behavioral design pattern. Interpreter pattern is used to defines a grammatical representation for a language and provides an interpreter to deal with this grammar.
- This pattern involves implementing an expression interface which tells to interpret a particular context. This pattern is used in SQL parsing, symbol processing engine etc.
- This pattern performs upon a hierarchy of expressions. Each expression here is a terminal or non-terminal.
- The tree structure of Interpreter design pattern is somewhat similar to that defined by the composite design pattern with terminal expressions being leaf objects and non-terminal expressions being composites.
- The tree contains the expressions to be evaluated and is usually generated by a parser. The parser itself is not a part of the interpreter pattern.
For Example : Here is the hierarchy of expressions for + – 9 8 7 :

Design components
- AbstractExpression (Expression): Declares an interpret() operation that all nodes (terminal and nonterminal) in the AST overrides.
- TerminalExpression (NumberExpression): Implements the interpret() operation for terminal expressions.
- NonterminalExpression (AdditionExpression, SubtractionExpression, and MultiplicationExpression): Implements the interpret() operation for all nonterminal expressions.
- Context (String): Contains information that is global to the interpreter. It is this String expression with the Postfix notation that has to be interpreted and parsed.
- Client (ExpressionParser): Builds (or is provided) the AST assembled from TerminalExpression and NonTerminalExpression. The Client invokes the interpret() operation.
Advantages
- It’s easy to change and extend the grammar. Because the pattern uses classes to represent grammar rules, you can use inheritance to change or extend the grammar. Existing expressions can be modified incrementally, and new expressions can be defined as variations on old ones.
- Implementing the grammar is easy, too. Classes defining nodes in the abstract syntax tree have similar implementations. These classes are easy to write, and often their generation can be automated with a compiler or parser generator.
Disadvantages
- Complex grammars are hard to maintain. The Interpreter pattern defines at least one class for every rule in the grammar. Hence grammars containing many rules can be hard to manage and maintain.
Iterator
Iterator is a behavioral design pattern that lets you traverse elements of a collection without exposing its underlying representation (list, stack, tree, etc.).
Collections are one of the most used data types in programming. Nonetheless, a collection is just a container for a group of objects.

Various types of collections.
Most collections store their elements in simple lists. However, some of them are based on stacks, trees, graphs and other complex data structures.
But no matter how a collection is structured, it must provide some way of accessing its elements so that other code can use these elements. There should be a way to go through each element of the collection without accessing the same elements over and over.
This may sound like an easy job if you have a collection based on a list. You just loop over all of the elements. But how do you sequentially traverse elements of a complex data structure, such as a tree? For example, one day you might be just fine with depth-first traversal of a tree. Yet the next day you might require breadth-first traversal. And the next week, you might need something else, like random access to the tree elements.

The same collection can be traversed in several different ways.
Adding more and more traversal algorithms to the collection gradually blurs its primary responsibility, which is efficient data storage. Additionally, some algorithms might be tailored for a specific application, so including them into a generic collection class would be weird.
On the other hand, the client code that’s supposed to work with various collections may not even care how they store their elements. However, since collections all provide different ways of accessing their elements, you have no option other than to couple your code to the specific collection classes.
Solution
The main idea of the Iterator pattern is to extract the traversal behavior of a collection into a separate object called an iterator.
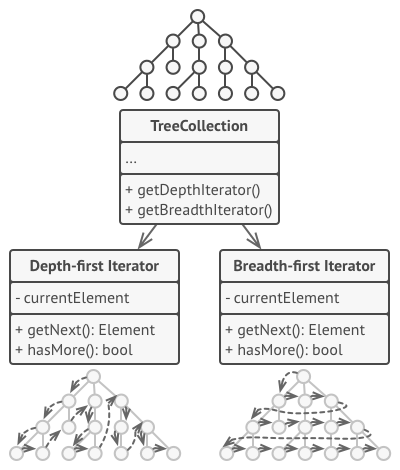
Iterators implement various traversal algorithms. Several iterator objects can traverse the same collection at the same time.
In addition to implementing the algorithm itself, an iterator object encapsulates all of the traversal details, such as the current position and how many elements are left till the end. Because of this, several iterators can go through the same collection at the same time, independently of each other.
Usually, iterators provide one primary method for fetching elements of the collection. The client can keep running this method until it doesn’t return anything, which means that the iterator has traversed all of the elements.
All iterators must implement the same interface. This makes the client code compatible with any collection type or any traversal algorithm as long as there’s a proper iterator. If you need a special way to traverse a collection, you just create a new iterator class, without having to change the collection or the client.
Real-World Analogy

Various ways to walk around Rome.
You plan to visit Rome for a few days and visit all of its main sights and attractions. But once there, you could waste a lot of time walking in circles, unable to find even the Colosseum.
On the other hand, you could buy a virtual guide app for your smartphone and use it for navigation. It’s smart and inexpensive, and you could be staying at some interesting places for as long as you want.
A third alternative is that you could spend some of the trip’s budget and hire a local guide who knows the city like the back of his hand. The guide would be able to tailor the tour to your likings, show you every attraction and tell a lot of exciting stories. That’ll be even more fun; but, alas, more expensive, too.
All of these options—the random directions born in your head, the smartphone navigator or the human guide—act as iterators over the vast collection of sights and attractions located in Rome.
Applicability
Use the Iterator pattern when your collection has a complex data structure under the hood, but you want to hide its complexity from clients (either for convenience or security reasons). The iterator encapsulates the details of working with a complex data structure, providing the client with several simple methods of accessing the collection elements. While this approach is very convenient for the client, it also protects the collection from careless or malicious actions which the client would be able to perform if working with the collection directly.
Use the pattern to reduce duplication of the traversal code across your app. The code of non-trivial iteration algorithms tends to be very bulky. When placed within the business logic of an app, it may blur the responsibility of the original code and make it less maintainable. Moving the traversal code to designated iterators can help you make the code of the application more lean and clean.
Use the Iterator when you want your code to be able to traverse different data structures or when types of these structures are unknown beforehand. The pattern provides a couple of generic interfaces for both collections and iterators. Given that your code now uses these interfaces, it’ll still work if you pass it various kinds of collections and iterators that implement these interfaces.
How to Implement
Declare the iterator interface. At the very least, it must have a method for fetching the next element from a collection. But for the sake of convenience you can add a couple of other methods, such as fetching the previous element, tracking the current position, and checking the end of the iteration.
Declare the collection interface and describe a method for fetching iterators. The return type should be equal to that of the iterator interface. You may declare similar methods if you plan to have several distinct groups of iterators.
Implement concrete iterator classes for the collections that you want to be traversable with iterators. An iterator object must be linked with a single collection instance. Usually, this link is established via the iterator’s constructor.
Implement the collection interface in your collection classes. The main idea is to provide the client with a shortcut for creating iterators, tailored for a particular collection class. The collection object must pass itself to the iterator’s constructor to establish a link between them.
Go over the client code to replace all of the collection traversal code with the use of iterators. The client fetches a new iterator object each time it needs to iterate over the collection elements.
Pros and Cons
- (+) Single Responsibility Principle. You can clean up the client code and the collections by extracting bulky traversal algorithms into separate classes.
- (+) Open/Closed Principle. You can implement new types of collections and iterators and pass them to existing code without breaking anything.
- (+) You can iterate over the same collection in parallel because each iterator object contains its own iteration state.
- (+) For the same reason, you can delay an iteration and continue it when needed.
- (-) Applying the pattern can be an overkill if your app only works with simple collections.
- (-) Using an iterator may be less efficient than going through elements of some specialized collections directly.
Memento
Memento is a behavioral design pattern that lets you save and restore the previous state of an object without revealing the details of its implementation.
Problem
Imagine that you’re creating a text editor app. In addition to simple text editing, your editor can format text, insert inline images, etc.
At some point, you decided to let users undo any operations carried out on the text. This feature has become so common over the years that nowadays people expect every app to have it. For the implementation, you chose to take the direct approach. Before performing any operation, the app records the state of all objects and saves it in some storage. Later, when a user decides to revert an action, the app fetches the latest snapshot from the history and uses it to restore the state of all objects.

Before executing an operation, the app saves a snapshot of the objects’ state, which can later be used to restore objects to their previous state.
Let’s think about those state snapshots. How exactly would you produce one? You’d probably need to go over all the fields in an object and copy their values into storage. However, this would only work if the object had quite relaxed access restrictions to its contents. Unfortunately, most real objects won’t let others peek inside them that easily, hiding all significant data in private fields.
Ignore that problem for now and let’s assume that our objects behave like hippies: preferring open relations and keeping their state public. While this approach would solve the immediate problem and let you produce snapshots of objects’ states at will, it still has some serious issues. In the future, you might decide to refactor some of the editor classes, or add or remove some of the fields. Sounds easy, but this would also require chaining the classes responsible for copying the state of the affected objects.

How to make a copy of the object’s private state?
But there’s more. Let’s consider the actual “snapshots” of the editor’s state. What data does it contain? At a bare minimum, it must contain the actual text, cursor coordinates, current scroll position, etc. To make a snapshot, you’d need to collect these values and put them into some kind of container.
Most likely, you’re going to store lots of these container objects inside some list that would represent the history. Therefore the containers would probably end up being objects of one class. The class would have almost no methods, but lots of fields that mirror the editor’s state. To allow other objects to write and read data to and from a snapshot, you’d probably need to make its fields public. That would expose all the editor’s states, private or not. Other classes would become dependent on every little change to the snapshot class, which would otherwise happen within private fields and methods without affecting outer classes.
It looks like we’ve reached a dead end: you either expose all internal details of classes, making them too fragile, or restrict access to their state, making it impossible to produce snapshots. Is there any other way to implement the "undo"?
Solution
All problems that we’ve just experienced are caused by broken encapsulation. Some objects try to do more than they are supposed to. To collect the data required to perform some action, they invade the private space of other objects instead of letting these objects perform the actual action.
The Memento pattern delegates creating the state snapshots to the actual owner of that state, the originator object. Hence, instead of other objects trying to copy the editor’s state from the “outside,” the editor class itself can make the snapshot since it has full access to its own state.
The pattern suggests storing the copy of the object’s state in a special object called memento. The contents of the memento aren’t accessible to any other object except the one that produced it. Other objects must communicate with mementos using a limited interface which may allow fetching the snapshot’s metadata (creation time, the name of the performed operation, etc.), but not the original object’s state contained in the snapshot.
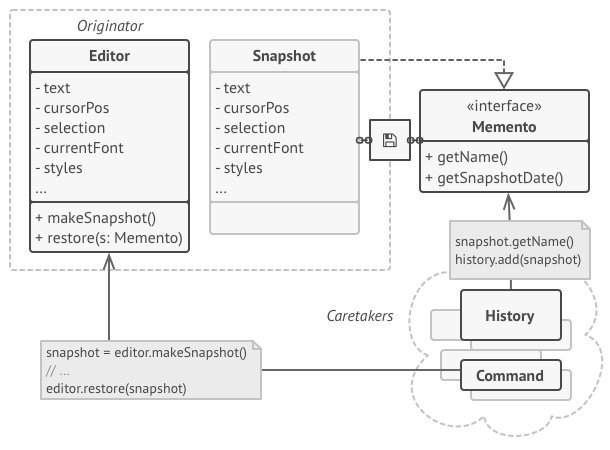
The originator has full access to the memento, whereas the caretaker can only access the metadata.
Such a restrictive policy lets you store mementos inside other objects, usually called caretakers. Since the caretaker works with the memento only via the limited interface, it’s not able to tamper with the state stored inside the memento. At the same time, the originator has access to all fields inside the memento, allowing it to restore its previous state at will.
In our text editor example, we can create a separate history class to act as the caretaker. A stack of mementos stored inside the caretaker will grow each time the editor is about to execute an operation. You could even render this stack within the app’s UI, displaying the history of previously performed operations to a user.
When a user triggers the undo, the history grabs the most recent memento from the stack and passes it back to the editor, requesting a roll-back. Since the editor has full access to the memento, it changes its own state with the values taken from the memento.
Pseudocode
In this example uses the Memento pattern alongside the Command pattern for storing snapshots of the complex text editor’s state and restoring an earlier state from these snapshots when needed.

Saving snapshots of the text editor’s state.
The command objects act as caretakers. They fetch the editor’s memento before executing operations related to commands. When a user attempts to undo the most recent command, the editor can use the memento stored in that command to revert itself to the previous state.
The memento class doesn’t declare any public fields, getters or setters. Therefore no object can alter its contents. Mementos are linked to the editor object that created them. This lets a memento restore the linked editor’s state by passing the data via setters on the editor object. Since mementos are linked to specific editor objects, you can make your app support several independent editor windows with a centralized undo stack.
Applicability
Use the Memento pattern when you want to produce snapshots of the object’s state to be able to restore a previous state of the object. The Memento pattern lets you make full copies of an object’s state, including private fields, and store them separately from the object. While most people remember this pattern thanks to the “undo” use case, it’s also indispensable when dealing with transactions (i.e., if you need to roll back an operation on error).
Use the pattern when direct access to the object’s fields/getters/setters violates its encapsulation. The Memento makes the object itself responsible for creating a snapshot of its state. No other object can read the snapshot, making the original object’s state data safe and secure.
How to Implement
Determine what class will play the role of the originator. It’s important to know whether the program uses one central object of this type or multiple smaller ones.
Create the memento class. One by one, declare a set of fields that mirror the fields declared inside the originator class.
Make the memento class immutable. A memento should accept the data just once, via the constructor. The class should have no setters.
If your programming language supports nested classes, nest the memento inside the originator. If not, extract a blank interface from the memento class and make all other objects use it to refer to the memento. You may add some metadata operations to the interface, but nothing that exposes the originator’s state.
Add a method for producing mementos to the originator class. The originator should pass its state to the memento via one or multiple arguments of the memento’s constructor. The return type of the method should be of the interface you extracted in the previous step (assuming that you extracted it at all). Under the hood, the memento-producing method should work directly with the memento class.
Add a method for restoring the originator’s state to its class. It should accept a memento object as an argument. If you extracted an interface in the previous step, make it the type of the parameter. In this case, you need to typecast the incoming object to the mediator class, since the originator needs full access to that object.
The caretaker, whether it represents a command object, a history, or something entirely different, should know when to request new mementos from the originator, how to store them and when to restore the originator with a particular memento.
The link between caretakers and originators may be moved into the memento class. In this case, each memento must be connected to the originator that had created it. The restoration method would also move to the memento class. However, this would all make sense only if the memento class is nested into originator or the originator class provides sufficient setters for overriding its state.
Pros and Cons
- (+) You can produce snapshots of the object’s state without violating its encapsulation.
- (+) You can simplify the originator’s code by letting the caretaker maintain the history of the originator’s state.
- (-) The app might consume lots of RAM if clients create mementos too often.
- (-) Caretakers should track the originator’s lifecycle to be able to destroy obsolete mementos.
- (-) Most dynamic programming languages, such as PHP, Python and JavaScript, can’t guarantee that the state within the memento stays untouched.
Observer
Observer is a behavioral design pattern that lets you define a subscription mechanism to notify multiple objects about any events that happen to the object they’re observing.
Problem
Imagine that you have two types of objects: a Customer and a Store. The customer is very interested in a particular brand of product (say, it’s a new model of the iPhone) which should become available in the store very soon.
The customer could visit the store every day and check product availability. But while the product is still en route, most of these trips would be pointless.
Visiting the store vs. sending spam
On the other hand, the store could send tons of emails (which might be considered spam) to all customers each time a new product becomes available. This would save some customers from endless trips to the store. At the same time, it’d upset other customers who aren’t interested in new products.
It looks like we’ve got a conflict. Either the customer wastes time checking product availability or the store wastes resources notifying the wrong customers.
Solution
The object that has some interesting state is often called subject, but since it’s also going to notify other objects about the changes to its state, we’ll call it publisher. All other objects that want to track changes to the publisher’s state are called subscribers.
The Observer pattern suggests that you add a subscription mechanism to the publisher class so individual objects can subscribe to or unsubscribe from a stream of events coming from that publisher. Fear not! Everything isn’t as complicated as it sounds. In reality, this mechanism consists of 1) an array field for storing a list of references to subscriber objects and 2) several public methods which allow adding subscribers to and removing them from that list.
{kind=link}
A subscription mechanism lets individual objects subscribe to event notifications.
Now, whenever an important event happens to the publisher, it goes over its subscribers and calls the specific notification method on their objects.
Real apps might have dozens of different subscriber classes that are interested in tracking events of the same publisher class. You wouldn’t want to couple the publisher to all of those classes. Besides, you might not even know about some of them beforehand if your publisher class is supposed to be used by other people.
That’s why it’s crucial that all subscribers implement the same interface and that the publisher communicates with them only via that interface. This interface should declare the notification method along with a set of parameters that the publisher can use to pass some contextual data along with the notification.
{kind=link}
Publisher notifies subscribers by calling the specific notification method on their objects.
If your app has several different types of publishers and you want to make your subscribers compatible with all of them, you can go even further and make all publishers follow the same interface. This interface would only need to describe a few subscription methods. The interface would allow subscribers to observe publishers’ states without coupling to their concrete classes.
Real-World Analogy
Magazine and newspaper subscriptions
{kind=link}
Magazine and newspaper subscriptions.
If you subscribe to a newspaper or magazine, you no longer need to go to the store to check if the next issue is available. Instead, the publisher sends new issues directly to your mailbox right after publication or even in advance.
The publisher maintains a list of subscribers and knows which magazines they’re interested in. Subscribers can leave the list at any time when they wish to stop the publisher sending new magazine issues to them.
Applicability
- Use the Observer pattern when changes to the state of one object may require changing other objects, and the actual set of objects is unknown beforehand or changes dynamically. You can often experience this problem when working with classes of the graphical user interface. For example, you created custom button classes, and you want to let the clients hook some custom code to your buttons so that it fires whenever a user presses a button.
The Observer pattern lets any object that implements the subscriber interface subscribe for event notifications in publisher objects. You can add the subscription mechanism to your buttons, letting the clients hook up their custom code via custom subscriber classes.
- Use the pattern when some objects in your app must observe others, but only for a limited time or in specific cases. The subscription list is dynamic, so subscribers can join or leave the list whenever they need to.
How to Implement
Look over your business logic and try to break it down into two parts: the core functionality, independent from other code, will act as the publisher; the rest will turn into a set of subscriber classes.
Declare the subscriber interface. At a bare minimum, it should declare a single update method.
Declare the publisher interface and describe a pair of methods for adding a subscriber object to and removing it from the list. Remember that publishers must work with subscribers only via the subscriber interface.
Decide where to put the actual subscription list and the implementation of subscription methods. Usually, this code looks the same for all types of publishers, so the obvious place to put it is in an abstract class derived directly from the publisher interface. Concrete publishers extend that class, inheriting the subscription behavior.
However, if you’re applying the pattern to an existing class hierarchy, consider an approach based on composition: put the subscription logic into a separate object, and make all real publishers use it.
Create concrete publisher classes. Each time something important happens inside a publisher, it must notify all its subscribers.
Implement the update notification methods in concrete subscriber classes. Most subscribers would need some context data about the event. It can be passed as an argument of the notification method.
But there’s another option. Upon receiving a notification, the subscriber can fetch any data directly from the notification. In this case, the publisher must pass itself via the update method. The less flexible option is to link a publisher to the subscriber permanently via the constructor.
- The client must create all necessary subscribers and register them with proper publishers.
Pros and Cons
- (+) Open/Closed Principle. You can introduce new subscriber classes without having to change the publisher’s code (and vice versa if there’s a publisher interface).
- (+) You can establish relations between objects at runtime.
- (-) Subscribers are notified in random order.
State
State is a behavioral design pattern that lets an object alter its behavior when its internal state changes. It appears as if the object changed its class.
Problem The State pattern is closely related to the concept of a Finite-State Machine.

Finite-State Machine
The main idea is that, at any given moment, there’s a finite number of states which a program can be in. Within any unique state, the program behaves differently, and the program can be switched from one state to another instantaneously. However, depending on a current state, the program may or may not switch to certain other states. These switching rules, called transitions, are also finite and predetermined.
You can also apply this approach to objects. Imagine that we have a Document class. A document can be in one of three states: Draft, Moderation and Published. The publish method of the document works a little bit differently in each state:
- In Draft, it moves the document to moderation.
- In Moderation, it makes the document public, but only if the current user is an administrator.
- In Published, it doesn’t do anything at all.
Possible states and transitions of a document object.
State machines are usually implemented with lots of conditional operators (if or switch) that select the appropriate behavior depending on the current state of the object. Usually, this “state” is just a set of values of the object’s fields. Even if you’ve never heard about finite-state machines before, you’ve probably implemented a state at least once. Does the following code structure ring a bell?
class Document is
field state: string
// ...
method publish() is
switch (state)
"draft":
state = "moderation"
break
"moderation":
if (currentUser.role == 'admin')
state = "published"
break
"published":
// Do nothing.
break
// ...
The biggest weakness of a state machine based on conditionals reveals itself once we start adding more and more states and state-dependent behaviors to the Document class. Most methods will contain monstrous conditionals that pick the proper behavior of a method according to the current state. Code like this is very difficult to maintain because any change to the transition logic may require changing state conditionals in every method.
The problem tends to get bigger as a project evolves. It’s quite difficult to predict all possible states and transitions at the design stage. Hence, a lean state machine built with a limited set of conditionals can grow into a bloated mess over time.
Solution
The State pattern suggests that you create new classes for all possible states of an object and extract all state-specific behaviors into these classes.
Instead of implementing all behaviors on its own, the original object, called context, stores a reference to one of the state objects that represents its current state, and delegates all the state-related work to that object.
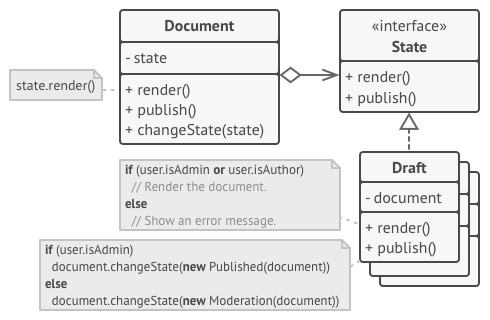
Document delegates the work to a state object
To transition the context into another state, replace the active state object with another object that represents that new state. This is possible only if all state classes follow the same interface and the context itself works with these objects through that interface.
This structure may look similar to the Strategy pattern, but there’s one key difference. In the State pattern, the particular states may be aware of each other and initiate transitions from one state to another, whereas strategies almost never know about each other.
Real-World Analogy
The buttons and switches in your smartphone behave differently depending on the current state of the device:
- When the phone is unlocked, pressing buttons leads to executing various functions.
- When the phone is locked, pressing any button leads to the unlock screen.
- When the phone’s charge is low, pressing any button shows the charging screen.
Applicability
Use the State pattern when you have an object that behaves differently depending on its current state, the number of states is enormous, and the state-specific code changes frequently. The pattern suggests that you extract all state-specific code into a set of distinct classes. As a result, you can add new states or change existing ones independently of each other, reducing the maintenance cost.
Use the pattern when you have a class polluted with massive conditionals that alter how the class behaves according to the current values of the class’s fields. The State pattern lets you extract branches of these conditionals into methods of corresponding state classes. While doing so, you can also clean temporary fields and helper methods involved in state-specific code out of your main class.
Use State when you have a lot of duplicate code across similar states and transitions of a condition-based state machine. The State pattern lets you compose hierarchies of state classes and reduce duplication by extracting common code into abstract base classes.
How to Implement
Decide what class will act as the context. It could be an existing class which already has the state-dependent code; or a new class, if the state-specific code is distributed across multiple classes.
Declare the state interface. Although it may mirror all the methods declared in the context, aim only for those that may contain state-specific behavior.
For every actual state, create a class that derives from the state interface. Then go over the methods of the context and extract all code related to that state into your newly created class.
While moving the code to the state class, you might discover that it depends on private members of the context. There are several workarounds:
- Make these fields or methods public.
- Turn the behavior you’re extracting into a public method in the context and call it from the state class. This way is ugly but quick, and you can always fix it later.
- Nest the state classes into the context class, but only if your programming language supports nesting classes.
In the context class, add a reference field of the state interface type and a public setter that allows overriding the value of that field.
Go over the method of the context again and replace empty state conditionals with calls to corresponding methods of the state object.
To switch the state of the context, create an instance of one of the state classes and pass it to the context. You can do this within the context itself, or in various states, or in the client. Wherever this is done, the class becomes dependent on the concrete state class that it instantiates.
Pros and Cons
- (+) Single Responsibility Principle. Organize the code related to particular states into separate classes.
- (+) Open/Closed Principle. Introduce new states without changing existing state classes or the context.
- (+) Simplify the code of the context by eliminating bulky state machine conditionals.
- (-) Applying the pattern can be overkill if a state machine has only a few states or rarely changes.
Visitor
Visitor is a behavioral design pattern that lets you separate algorithms from the objects on which they operate.
Problem
Imagine that your team develops an app which works with geographic information structured as one colossal graph. Each node of the graph may represent a complex entity such as a city, but also more granular things like industries, sightseeing areas, etc. The nodes are connected with others if there’s a road between the real objects that they represent. Under the hood, each node type is represented by its own class, while each specific node is an object.
Exporting the graph into XML.
At some point, you got a task to implement exporting the graph into XML format. At first, the job seemed pretty straightforward. You planned to add an export method to each node class and then leverage recursion to go over each node of the graph, executing the export method. The solution was simple and elegant: thanks to polymorphism, you weren’t coupling the code which called the export method to concrete classes of nodes.
Unfortunately, the system architect refused to allow you to alter existing node classes. He said that the code was already in production and he didn’t want to risk breaking it because of a potential bug in your changes.
The XML export method had to be added into all node classes, which bore the risk of breaking the whole application if any bugs slipped through along with the change.
Besides, he questioned whether it makes sense to have the XML export code within the node classes. The primary job of these classes was to work with geodata. The XML export behavior would look alien there.
There was another reason for the refusal. It was highly likely that after this feature was implemented, someone from the marketing department would ask you to provide the ability to export into a different format, or request some other weird stuff. This would force you to change those precious and fragile classes again.
Solution
The Visitor pattern suggests that you place the new behavior into a separate class called visitor, instead of trying to integrate it into existing classes. The original object that had to perform the behavior is now passed to one of the visitor’s methods as an argument, providing the method access to all necessary data contained within the object.
Now, what if that behavior can be executed over objects of different classes? For example, in our case with XML export, the actual implementation will probably be a little bit different across various node classes. Thus, the visitor class may define not one, but a set of methods, each of which could take arguments of different types, like this:
class ExportVisitor implements Visitor is
method doForCity(City c) { ... }
method doForIndustry(Industry f) { ... }
method doForSightSeeing(SightSeeing ss) { ... }
// ...
But how exactly would we call these methods, especially when dealing with the whole graph? These methods have different signatures, so we can’t use polymorphism. To pick a proper visitor method that’s able to process a given object, we’d need to check its class. Doesn’t this sound like a nightmare?
foreach (Node node in graph)
if (node instanceof City)
exportVisitor.doForCity((City) node)
if (node instanceof Industry)
exportVisitor.doForIndustry((Industry) node)
// ...
}
You might ask, why don’t we use method overloading? That’s when you give all methods the same name, even if they support different sets of parameters. Unfortunately, even assuming that our programming language supports it at all (as Java and C# do), it won’t help us. Since the exact class of a node object is unknown in advance, the overloading mechanism won’t be able to determine the correct method to execute. It’ll default to the method that takes an object of the base Node class.
However, the Visitor pattern addresses this problem. It uses a technique called Double Dispatch, which helps to execute the proper method on an object without cumbersome conditionals. Instead of letting the client select a proper version of the method to call, how about we delegate this choice to objects we’re passing to the visitor as an argument? Since the objects know their own classes, they’ll be able to pick a proper method on the visitor less awkwardly. They “accept” a visitor and tell it what visiting method should be executed.
// Client code
foreach (Node node in graph)
node.accept(exportVisitor)
// City
class City is
method accept(Visitor v) is
v.doForCity(this)
// ...
// Industry
class Industry is
method accept(Visitor v) is
v.doForIndustry(this)
// ...
I confess. We had to change the node classes after all. But at least the change is trivial and it lets us add further behaviors without altering the code once again.
Now, if we extract a common interface for all visitors, all existing nodes can work with any visitor you introduce into the app. If you find yourself introducing a new behavior related to nodes, all you have to do is implement a new visitor class.
Real-World Analogy
A good insurance agent is always ready to offer different policies to various types of organizations.
Imagine a seasoned insurance agent who’s eager to get new customers. He can visit every building in a neighborhood, trying to sell insurance to everyone he meets. Depending on the type of organization that occupies the building, he can offer specialized insurance policies:
- If it’s a residential building, he sells medical insurance.
- If it’s a bank, he sells theft insurance.
- If it’s a coffee shop, he sells fire and flood insurance.
Applicability
Use the Visitor when you need to perform an operation on all elements of a complex object structure (for example, an object tree). The Visitor pattern lets you execute an operation over a set of objects with different classes by having a visitor object implement several variants of the same operation, which correspond to all target classes.
Use the Visitor to clean up the business logic of auxiliary behaviors. The pattern lets you make the primary classes of your app more focused on their main jobs by extracting all other behaviors into a set of visitor classes.
Use the pattern when a behavior makes sense only in some classes of a class hierarchy, but not in others. You can extract this behavior into a separate visitor class and implement only those visiting methods that accept objects of relevant classes, leaving the rest empty.
How to Implement
Declare the visitor interface with a set of “visiting” methods, one per each concrete element class that exists in the program.
Declare the element interface. If you’re working with an existing element class hierarchy, add the abstract “acceptance” method to the base class of the hierarchy. This method should accept a visitor object as an argument.
Implement the acceptance methods in all concrete element classes. These methods must simply redirect the call to a visiting method on the incoming visitor object which matches the class of the current element.
The element classes should only work with visitors via the visitor interface. Visitors, however, must be aware of all concrete element classes, referenced as parameter types of the visiting methods.
For each behavior that can’t be implemented inside the element hierarchy, create a new concrete visitor class and implement all of the visiting methods. You might encounter a situation where the visitor will need access to some private members of the element class. In this case, you can either make these fields or methods public, violating the element’s encapsulation, or nest the visitor class in the element class. The latter is only possible if you’re lucky to work with a programming language that supports nested classes.
The client must create visitor objects and pass them into elements via “acceptance” methods.
Pros and Cons
- (+) Open/Closed Principle. You can introduce a new behavior that can work with objects of different classes without changing these classes.
- (+) Single Responsibility Principle. You can move multiple versions of the same behavior into the same class.
- (+) A visitor object can accumulate some useful information while working with various objects. This might be handy when you want to traverse some complex object structure, such as an object tree, and apply the visitor to each object of this structure.
- (-) You need to update all visitors each time a class gets added to or removed from the element hierarchy.
- (-) Visitors might lack the necessary access to the private fields and methods of the elements that they’re supposed to work with.
Patterns of Enterprise Architecture Applications
Domain Layer Patterns
Transaction Script (Сценнарий транзакции)
Организует бизнес-логику в процедуры, которые управляют каждая своим запросом.
Большинство бизнес-приложений можно представить в виде набора транзакций. Какие-то из них выбират данные, какие-то ‐ меняют. Каждое взаимодействие пользователя и системы содержит определённый набор действий. В некоторых случаях это может быть просто вывод данных из БД. В других случаях эти дествия могут содержать в себе множество вычислений и проверок.
Паттерн Transaction Script организует всю эту логику в одну процедуру, работая в БД напрямую или через тонкую обёртку. Каждая транзакция имеет свой Transaction Script, хотя общие подзадачи могкт быть разбиты на процедуры.

Example: Пользователю необходимо заказать номер в гостиннице, соответствующая процедура должна предусматривать действия по проверке наличия подходящего номера, вычислению суммы оплаты и фиксации заказа в базе данных. Задача - получить входную информацию, опросить базу данных, сделать выводы и сохранить результаты
Существует два способа разнесения кода сценариев транзакции по классам. Наиболее общий, прямолинейный - использование одного класса для реализации нескольких сценариев транзакции. Второй, следующий схеме типового решения Command, связан с разработкой собственного класса для каждого сценария транзакции
Domain Model
Объектная модель домена, объединяющая свойста (данные) и поведение (функции).
К сожалению, бизнес-логика приложения может быть очень сложной. Правила и логика описывают множество случаев и модификаций поведения. Для обработки всей этой сложной логики и проектируются объекты. Паттерн Domain Model (модель области определения) образует сеть взаимосвязанных объектов, в которой каждый объект представляет собой отдельную значащую сущность: может быть настолько большую, как корпорация или настолько малую, как строка из формы заказа.
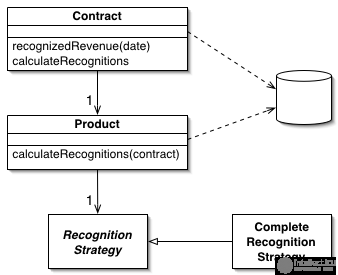
Можно выделить две разновидности - "Простая" во многом походит на схему базы данных и содержит, как правило, по одному объекту домена в расчете на каждую таблицу. "Сложная" модель может отличаться от структуры базы данных и содержать иерархии наследования, стратегии и типовые решения, а также сложные сети мелких взаимосвязанных объектов
Table Module
Одна сущность обрабатывает всю бизнес-логику для всех строк таблице БД или виде.
Один из основополагающих принципов в ООП - сочетание данных и методов обработки этих данных. Традиционный объектно-ориентированный подход основан на объектах с соответствием, как, например, в паттерне Domain Model. Таким образом, если есть класс Employee, люой экземпляр этого класса соответствует конкретному работнику. Эта структура работает хорошо, потому что, имея связь, можно выполнять операции, использователь отношения, и собирать данные о работнике
Одна из проблем в паттерне Domain Model заключается в интерфейсе к БД. Этот подход относится к БД, как к сумашедшей тётушке, запертой на чердаке, с которой никто не хочет говорить. Частенько, приходится сильно постараться, чтобы записать или считать данные из БД, преобразуя их между двумя представлениями.
Паттерн Table Module разделяет логику области определения (домена) на отдельные классы для каждой таблицы в БД и один экземпляр класса содержит различные процедуры, работающие с данными. Основное отличие от Domain Model заключается в том, что если есть несколько заказов, то Domain Model будет создавать для каждого из заказов свой объект, а Table Moduleбудет управлять всем заказами при помощи одного объекта.
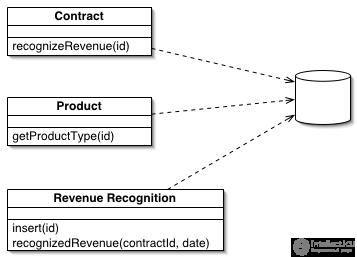
Service Layer
Определяет границу между приложением и слоем сервисов, который образует набор доступных операций и управляет ответом приложения в каждой операции.
Бизнес-приложения обычно нуждаются в различных интерфейсах к данным, которые они хранят и логике, которую реализуют: загрузчики данных, пользовательские интерфейсы, интеграционные шлюзы и другое. Вопреки различным целям, эти интерфейсы часто нуждаются во взаимодействии с приложением для доступа и управления его данными и исполнения логики. Эти взаимодействия могут быть сложными, использующими транзакции на нескольких ресурсах и управление несколькими ответами на действие. Программирование логики взаимодействия для каждого интерфейса вызовет больше количество дублирования.
Паттерн Service Layer определяет для приложения границу и набор допустимых операций с точки зрения взаимодействующих с ним клиентских. Он инкапсулирует бизнес-логику приложения, управляя транзакциями и управляя ответами в реализации этих операций.
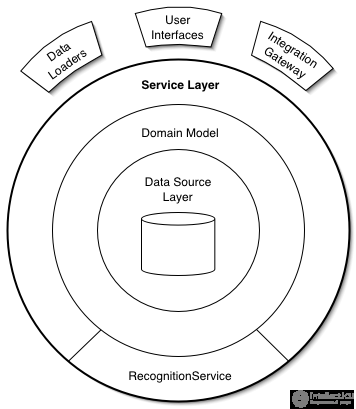
Object / Relational Metadata Mapping Patterns
Metadata Mapping (Распределение на основе метаданных)

Хранит данные об объектно-реляционном распределении в метаданных
В большинстве случаев, код, управляющий объектно-реляционным распределением описывает, как поля в БД соотносятся с полями в объектах. Такой код получается сильно повторяющимся и скучным. Паттерн Metadata Mapping позволяет разработчикам определять правила распределения (маппинга) в простой табличной форме, которая может быть обработана общим кодом, который получает данные о правилах записи и чтения данных из БД.
Query Object (Объект-запрос)
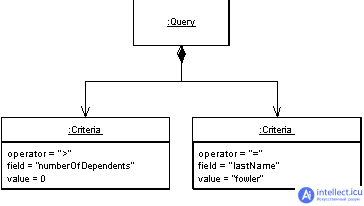
Объект, представляющий запрос к БД
SQL зачастую сопряженно используемый язык и многие разработчики не совсем хорошо в нём разбираются. Более того, необходимо знать, как выглядит структура базы данных, чтобы создавать запросы. Можно избежать этого, создав специальные методы поиска, которые сожержат в себе весь SQL и управляются ограниченным набором параметров. Такой подход делает сложным создание и тюнинг запросов для конкретных ситуаций. Также это ведёт к дублированию в SQL-выражениях.
Паттерн Query Object - это структура объектов, которая может интерпретироваться в SQL-запрос. Можно создавать такой запрос ссылаясь на классы и поля так же как на таблицы и столбцы. Таким образом создаётся независимость разработчика от струткуры БД и конкретной реализации БД.
Repository (Репозиторий)
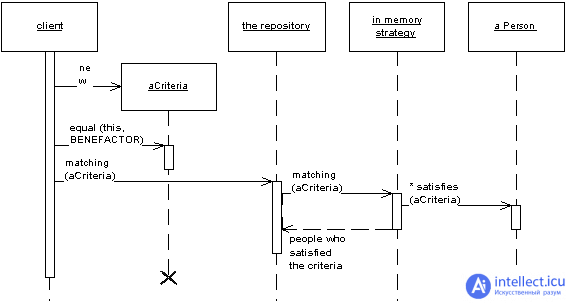
Посредничает между уровнями области определения и распределения данных (domain and data mapping layers), используя интерфейс, схожий с коллекциями для доступа к объектам области определения.
Система со сложной моделью области определения может быть упрощена при помощи дополнительного уровня, например Data Mapper, который бы изолировал объекты от кода доступа к БД. В таких системах может быть полезным добавление ещё одного слоя абстракции поверх слоя распределения данных (Data Mapper), в котором бы был собран код создания запросов. Это становится ещё более важным, когда в области определения множество классов или при сложных, тяжелых запросах. В таких случаях добавление этого уровня особенно помогает сократить дублирование кода запросов.
Паттерн Repository посредничает между слоем области определения и слоем распределения данных, работая, как обычная колекция объектов области определения. Объекты-клиенты создают описание запроса декларативно и направляют их к объекту-репозиторию (Repository) для обработки. Объекты могут быть добавлены или удалены из репозитория, как будто они формируют простую коллекцию объектов. А код распределения данных, скрытый в объекте Repository, позаботится о соответсвующих операциях в незаметно для разработчика. В двух словах, паттерн Repository инкапсулирует объекты, представленыые в хранилище данных и операции, производимые над ними, предоставляя более объектно-ориентированное представление реальных данных. Repository также преследует цель достижения полного разделения и односторонней зависимости между уровнями области определения и распределения данных.
Distribution Patterns
Remote Facade (Парадный вход)
Предоставляет общий объединяющий интерфейс для набора методов объекта для улучшения эффективности сетевого взаимодействия.
Паттерн Remote Facade в объектно-ориентированной модели улучшает работу с маленькими объектами, у которых маленькие методы. Маленькие методы открывают большие возможности для контроля и изменения поведения, а также для улучшения понимания клиентом работы приложения. Одно из последствий такого "мелко-молотого" поведения в том, что обычно происходит много взаимодействий между объектами с вызовом множества методов.
В одном адресном пространстве "мелко-молотые" взаимодействия работаю хорошо, но всё меняется, когда происходит взаимодействие между процессами. Удалённые вызовы более затратны, потому что многое надо сделать: иногда данные нужно упорядочить, проверить на безопасность, пакеты должны быть маршрутизированы на свичах. Если два процесса работают на разных краях света, даже скорость света может играть роль. Тяжелая правда в том, что любые межпроцессные взаимодействия на порядок более расточительны, чем анутрипроцессные вызовы. Даже, если оба процесса работают на одной машине. Такое влияние на производительность не может быть упущено из вида, даже приверженцами ленивой оптимизации.
В результате любой объект, который задействован в удалённом взаимодействии, нуждается в более общем интерфейсе, который бы позволил минимизировать количество запросов, необходимых, чтобы сделать что-либо. Это затрагивает не только методы, но и объекты. Вместо того, чтобы запрашивать счёт и все его пункты отдельно, надо считать и обновить все пункты счёта за одно обращение. Это влияет на всю структуру объекта. Надо забыть о благой цели малых объектов и малых методов. Программирование становится всё сложнее, продуктивность падает и падает.
Паттерн Remote Facade представляет собой общий "Фасад" (по GoF) поверх структуры более "мелко-молотых" объектов. Ни один из этих объектов не имеет удалённого интерфейса, а Remote Facade не включает в себя никакой бизнес-логики. Всё, что делает Remote Facade - это транслирует общие запросы в набор небольших запросов к подчинённым объектам.
Data Transfer Object (Объект передачи данных)
Объект, который пересылает данные между процессами для уменьшения количества вызовов методов.
При работе с удалённым интерфейсом, таким как, например, Remote Facade, каждый запрос к нему достаточно затратен. В результате, приходится уменьшать количество вызовов, что означает необходимость передачи большего количества данных за один вызов. Чтобы реализовать это, как вариант, можно использовать множество прааметров. Однако, при этом зачастую код получается неуклюжим и неудобным. Также это часто невозможно в таких языках, как Java, которые возвращают лишь одно значение.
Решением здесь является паттерн Data Transfer Object, который может хранить всю необходимую для вызова информацию. Он должен быть сериализуемым для удобной передачи по сети. Обычно используется объект-сборщик для передачи данных между DTO и объектами в приложении.