Qualified
Number" is a data type, and "Age" is a
domain. To give another example, "StreetName" and "Surname" might both be represented as text fields, but they are obviously different kinds of text fields; they belong to different domains.
Relational terminology: Entities
entity is anything about which the system needs to store information.
The nouns "Customers," "Products," "Employees," and "Suppliers" are all clearly entities. The events represented by the verbs "buy" and "sell" are also entities
Most entities model objects or events in the physical world: customers, products, or sales calls. These are concrete entities. Entities can also model abstract concepts. The most common example of an abstract entity is one that models the relationship between other entities—for example, the fact that a certain sales representative is responsible for a certain client or that a certain student is enrolled in a certain class.
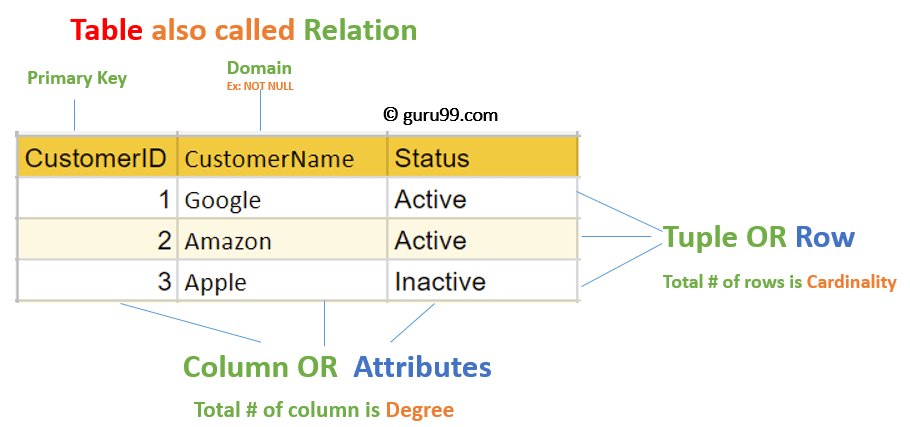
Relational terminology: Attributes
- each column in the
tupleis called anattribute - the number of attributes in a relation determines its
degree - the
domainof anattributeis the "kind" of data it represents (domain is not the same as a data type)
Relational terminology: Records (Tuples)
- each row of data in table is a
tuple - the number of tuples in a relation(table) determines its
cardinality
Relationships (One-to-One, One-to-Many)
one-to-many
Организовывается с помощью 2х таблиц и завязки первичных ключей
Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
many-to-many
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B).
Школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
Соединительная таблица всегда имеет составной первичный ключ.
Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
one-to-one
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
В одной таблице.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
- Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
Understanding ER notation
E/R diagrams use rectangles to describe entities, ellipses for attributes, and diamonds to represent relationships
The nature of the relationship between entities (one-to-one, one-to-many, or many-to-many) is represented in various ways. A number of people use 1 and M or 1 and ¥ (representing infinity) to represent one and many.
or "crow's foot" technique:

Understanding normalization concept
в ненормализированной форме таблица может хранить информацию о двух или более сущностях, содержать повторяющиеся столбцы, столбцы могут содержать повторяющиеся значения
процесс организации данных в базе, включает создание таблиц и установление отношений между ними, устранение избыточности и дублирования данных
Существует несколько правил нормализации БД, каждое правило называется "нормальной формой"
Первая
- устранить повторяющиеся группы в отдельных таблицах.
- создать отдельную таблицу для каждого набора связанных данных
- идентифицировать каждый набор связанных данных с помощью первичного ключа
Вторая
- Создать отдельные таблицы для наборов значений, относящихся к нескольким записям.
- Связать эти таблицы с помощью внешнего ключа.
Третья
- устранить поля, не зависящие от ключа.
функциональная зависимость- описывает связь между атрибутами отношения. Например, если атрибут В функционально зависит от атрибута А (А → В), то каждое значение атрибута А связано только с одним значением атрибута В.
Пример
1НФ
| Фирма | Модели |
|---|---|
| BMW | M5, X5M, M1 |
| Nissan | GT-R |
нарушение 1НФ происходит в модели BMW, так как в одной ячейке содержится несколько моделей, исправляем:
| Фирма | Модели |
|---|---|
| BMW | M5 |
| BMW | X5M |
| BMW | M1 |
| Nissan | GT-R |
2НФ
| Модель | Фирма | Цена | Скидка |
|---|---|---|---|
| M5 | BMW | 550 000 | 5% |
| X5M | BMW | 600 000 | 5% |
| M1 | BMW | 250 000 | 5% |
| GT-R | Nissan | 500 000 | 10% |
таблица находится в 1НФ.
- Цена зависит от Модели и Фирмы
- Скидка зависит от Фирмы
исправляем, разбив на 2 таблицы
| Модель | Фирма | Цена |
|---|---|---|
| M5 | BMW | 550 000 |
| X5M | BMW | 600 000 |
| M1 | BMW | 250 000 |
| GT-R | Nissan | 500 000 |
и вторая таблица
| Фирма | Скидка |
|---|---|
| BMW | 5% |
| Nissan | 10% |
3НФ
| Модель | Магазин | Телефон |
|---|---|---|
| BMW | Риал-авто | 87-33-98 |
| Audi | Риал-авто | 87-33-98 |
| Nissan | Некст-Авто | 94-54-12 |
тут Модель является первичным ключем, а телефон зависит от Фирма функциональные зависимости:
- Модель -> Магазин
- Магазин -> Телефон
- Модель -> Телефон (транзитивна - не прямая)
исправляем
| Магазин | Телефон |
|---|---|
| Риал-авто | 87-33-98 |
| Некст-Авто | 94-54-12 |
и вторая
| Модель | Магазин |
|---|---|
| BMW | Риал-авто |
| Audi | Риал-авто |
| Nissan | Некст-Авто |
Первая нормальная форма (1НФ) требует, чтобы каждое поле таблицы БД:
было неделимым;
не содержало повторяющихся групп.
Неделимость поля означает, что значение поля не должно делиться на более мелкие значения. Например, если в поле "Подразделение" содержится название факультета и название кафедры, требование неделимости не соблюдается и необходимо из данного поля выделить или название факультета, или кафедры в отдельное поле.
Повторяющимися являются поля, содержащие одинаковые по смыслу значения. Например, если требуется получить статистику сдачи экзаменов по предметам, можно создать поля для хранения данных об оценке по каждому предмету. Однако в этом случае мы имеем дело с повторяющимися группами.
Вторая нормальная форма (2НФ) требует, чтобы все поля таблицы зависели от первичного ключа, то есть, чтобы первичный ключ однозначно определял запись и не был избыточен. Те поля, которые зависят только от части первичного ключа, должны быть выделены в составе отдельных таблиц.
Третья нормальная форма (ЗНФ) требует, чтобы значение любого поля таблицы, не входящего в первичный ключ, не зависело от значения другого поля, не входящего в первичный ключ.
Data Integrity
Data integrity refers to the accuracy and consistency (validity) of data over its lifecycle. Compromised data, after all, is of little use to enterprises, not to mention the dangers presented by sensitive data loss. For this reason, maintaining data integrity is a core focus of many enterprise security solutions.
Data integrity can be compromised in several ways. Each time data is replicated or transferred, it should remain intact and unaltered between updates. Error checking methods and validation procedures are typically relied on to ensure the integrity of data that is transferred or reproduced without the intention of alteration.
Data integrity refers to the fact that data must be reliable and accurate over its entire lifecycle. Data integrity and data security go hand in hand, even though they’re separate concepts. Uncorrupted data (integrity) is considered to be whole and then stay unchanged relative to that complete state.
Maintaining or keeping data consistent throughout its lifecycle is a matter of protecting it (security) so that it’s reliable. And data that’s reliable is simply able to meet certain standards, with which compliance is necessary. For example, the FDA uses the acronym ALCOA to define data integrity standards and to relate to good manufacturing practices.
Data is expected to be:
- Attributable – Data should clearly demonstrate who observed and recorded it, when it was observed and recorded, and who it is about.
- Legible – Data should be easy to understand, recorded permanently and original entries should be preserved.
- Contemporaneous – Data should be recorded as it was observed, and at the time it was executed.
- Original – Source data should be accessible and preserved in its original form.
- Accurate – Data should be free from errors, and conform with the protocol.
4 Type of Data Integrity
In the database world, data integrity is often placed into the following types:
- Entity Integrity: In a database, there are columns, rows, and tables. In a primary key, these elements are to be as numerous as needed for the data to be accurate, yet no more than necessary. None of these elements should be the same and none of these elements should be null. For example, a database of employees should have primary key data of their name and a specific “employee number.”
- Referential Integrity: Foreign keys in a database is a second table that can refer to a primary key table within the database. Foreign keys relate data that could be shared or null. For instance, employees could share the same role or work in the same department.
- Domain Integrity: All categories and values in a database are set, including nulls (e.g., N/A). The domain integrity of a database refers to the common ways to input and read this data. For instance, if a database uses monetary values to include dollars and cents, three decimal places will not be allowed.
- User-Defined Integrity: There are sets of data, created by users, outside of entity, referential and domain integrity. If an employer creates a column to input corrective action of employees, this data would be classified as “user-defined.”
Phylosofy of NoSQL data-bases
NoSQL
In computing, NoSQL (mostly interpreted as "not only SQL") is a broad class of database management systems identified by its non-adherence to the widely used relational database management system model; that is, NoSQL databases are not primarily built on tables, and as a result, generally do not use SQL for data manipulation.
- Не используется SQL
- Неструктурированные (schemaless)
- Представление данных в виде агрегатов (aggregates)
- Слабые ACID свойства
- Распределенные системы, без совместно используемых ресурсов (share nothing).
- Репликация — копирование данных на другие узлы при обновлении. Позволяет как добиться большей масштабируемости, так и повысить доступность и сохранность данных. master-slave, peer-to-peer
- Шардинг — разделение данных по узлам 8 NoSQL базы в-основном оупенсорсные и созданы в 21 столетии
В базах данных NoSQL для доступа к данным и управления ими применяются различные модели данных, в том числе документная, графовая, поисковая, с использованием пар «ключ‑значение» и хранением данных в памяти. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе. В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации. Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
- Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных (например, документной, графовой или с использованием пар «ключ‑значение») и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.
SQL vs NoSQL
| Parameter | SQL | NOSQL |
|---|---|---|
| Definition | SQL databases are primarily called RDBMS or Relational Databases | NoSQL databases are primarily called as Non-relational or distributed database |
| Design for | Traditional RDBMS uses SQL syntax and queries to analyze and get the data for further insights. They are used for OLAP systems. | NoSQL database system consists of various kind of database technologies. These databases were developed in response to the demands presented for the development of the modern application. |
| Query Language | Structured query language (SQL) | No declarative query language |
| Type | SQL databases are table based databases | NoSQL databases can be document based, key-value pairs, graph databases |
| Schema | SQL databases have a predefined schema | NoSQL databases use dynamic schema for unstructured data. |
| Ability to scale | SQL databases are vertically scalable | NoSQL databases are horizontally scalable |
| Examples | Oracle, Postgres, and MS-SQL. | MongoDB, Redis, , Neo4j, Cassandra, Hbase. |
| Best suited for | An ideal choice for the complex query intensive environment. | It is not good fit complex queries. |
| Hierarchical data storage | SQL databases are not suitable for hierarchical data storage. | More suitable for the hierarchical data store as it supports key-value pair method. |
| Variations | One type with minor variations. | Many different types which include key-value stores, document databases, and graph databases. |
| Development Year | It was developed in the 1970s to deal with issues with flat file storage | Developed in the late 2000s to overcome issues and limitations of SQL databases. |
| Open-source | A mix of open-source like Postgres & MySQL, and commercial like Oracle Database. | Open-source |
| Consistency | It should be configured for strong consistency. | It depends on DBMS as some offers strong consistency like MongoDB, whereas others offer only offers eventual consistency, like Cassandra. |
| Best Used for | RDBMS database is the right option for solving ACID problems. | NoSQL is a best used for solving data availability problems |
| Importance | It should be used when data validity is super important | Use when it's more important to have fast data than correct data |
| Best option | When you need to support dynamic queries | Use when you need to scale based on changing requirements |
| Hardware | Specialized DB hardware (Oracle Exadata, etc.) | Commodity hardware |
| Network | Highly available network (Infiniband, Fabric Path, etc.) | Commodity network (Ethernet, etc.) |
| Storage Type | Highly Available Storage (SAN, RAID, etc.) | Commodity drives storage (standard HDDs, JBOD) |
| Best features | Cross-platform support, Secure and free | Easy to use, High performance, and Flexible tool. |
| Top Companies Using | Hootsuite, CircleCI, Gauges | Airbnb, Uber, Kickstarter |
| Average salary | The average salary for any professional SQL Developer is $84,328 per year in the U.S.A. | The average salary for "NoSQL developer" ranges from approximately $72,174 per year |
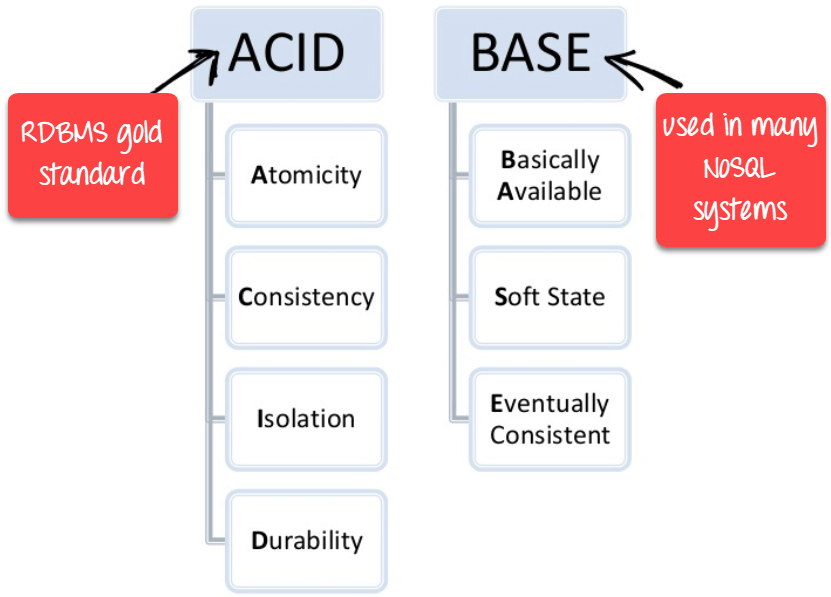
| ACID vs. BASE Model | ACID( Atomicity, Consistency, Isolation, and Durability) is a standard for RDBMS | Base ( Basically Available, Soft state, Eventually Consistent) is a model of many NoSQL systems |
When use SQL?
- SQL is the easiest language used to communicate with the RDBMS
- Analyzing behavioral related and customized sessions
- Building custom dashboards
- It allows you to store and gets data from the database quickly
- Preferred when you want to use joins and execute complex queries
When use NoSQL?
- When ACID support is not needed
- When Traditional RDBMS model is not enough
- Data which need a flexible schema
- Constraints and validations logic not required to be implemented in database
- Logging data from distributed sources
- It should be used to store temporary data like shopping carts, wish list and session data
Types of NOsql DB
Some articles mention four main types, others six, but in this post we’ll go through the five main types of NoSQL databases, namely wide-column store, document store, key-value store, graph store, and multi-model.
- Wide-Column Store
- Document Store
- Key-Value Data Store
- Graph Store
- Multi-Model
Wide-Column Store
As the name suggests, wide-column stores use columns to store data. You can group related columns into column families. Individual rows then constitute a column family.
A typical column family contains a row key as the first column, which uniquely identifies that row within the column family. The following columns then contain a column key, which uniquely identifies that column within the row, so that you can query their corresponding column values.
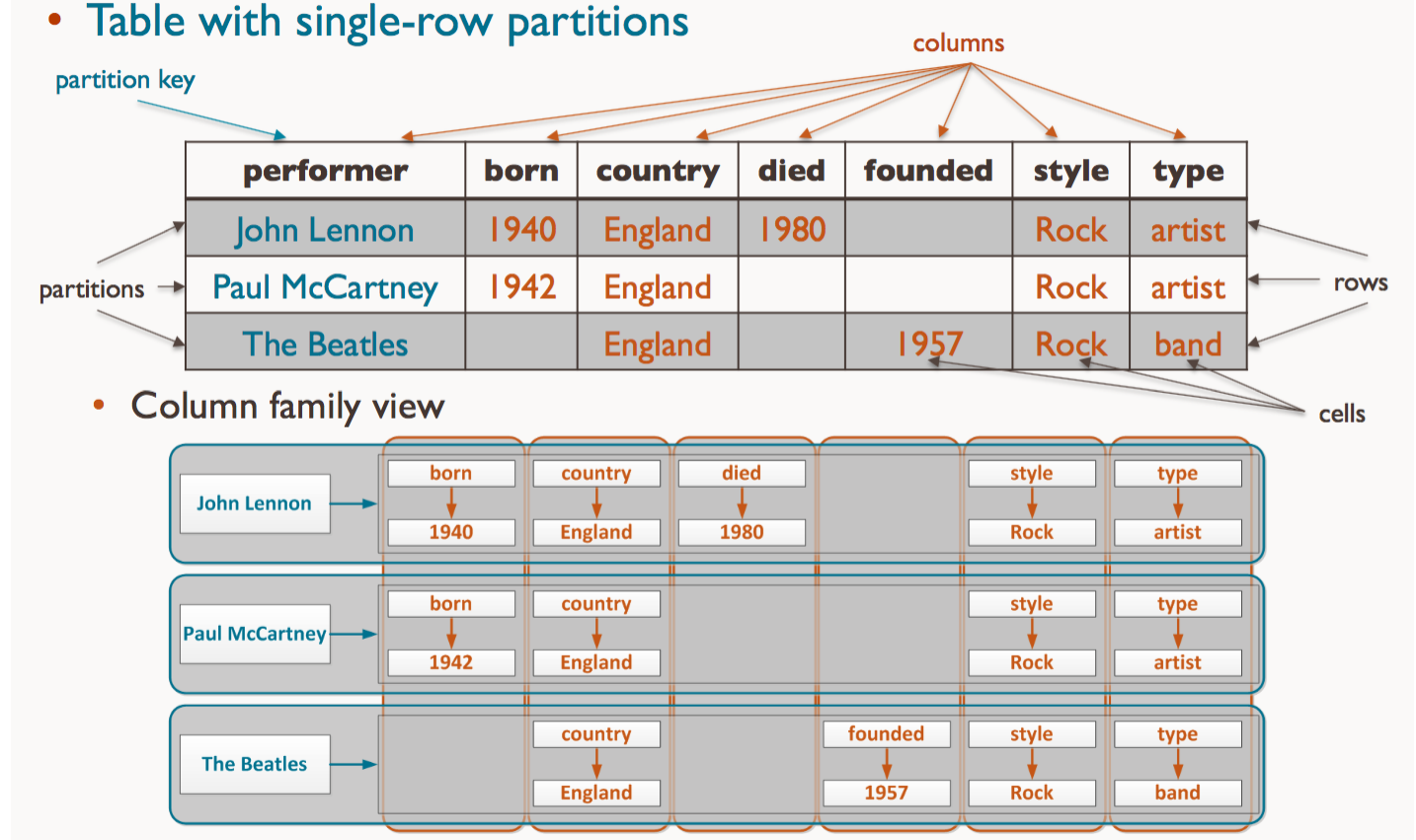
Examples of Column Databases
- Cassandra – Free, open-source
- HBase – Free, open-source
TIP
Column stores offer very high performance and a highly scalable architecture. Because they’re fast to load and query, they’ve been popular among companies and organizations dealing with big data, IoT, and user recommendation and personalization engines.
Document Store
Document store databases use JSON, XML, or BSON documents to store data. You can pretty much fill in a document with whatever data you want. Documents can have different structures, but you can index common fields for faster performance.
Here’s an example of a document in MongoDB:

Examples of Document Databases:
- MongoDB – Free, open-source
- Couchbase – Free, open-source
Use Cases
- SEGA uses MongoDB for handling 11 million in-game accounts
- Cisco moved its VSRM (video session and research manager) platform to Couchbase to achieve greater scalability
- Aer Lingus uses MongoDB with Studio 3T to handle ticketing and internal apps
- Built on MongoDB, The Weather Channel’s iOS and Android apps deliver weather alerts to 40 million users in real-time
Key-Value Data Store
Key-value databases store data in unique key-value pairs, meaning each key is associated only with one value in a collection, like in a dictionary. This makes querying a key-value data store fast because of its simple model. There’s no query language needed. Data retrieval is a simple matter of using get, put, and delete commands.
Examples:
- Redis – Free, open-source
- Memcached – Free, open-source
Key-value data stores are ideal for storing user profiles, blog comments, product recommendations, and session information.
- Twitter uses Redis to deliver your Twitter timeline
- Pinterest uses Redis to store lists of users, followers, unfollowers, boards, and more
- Coinbase uses Redis to enforce rate limits and guarantee correctness of Bitcoin transactions
- Quora uses Memcached to cache results from slower, persistent databases
Graph Store
Nodes and relationships are the bases of graph databases. A node represents an entity, like a user, category, or a piece of data. A relationship represents how two nodes are associated.
Graph databases use nodes that contain lists of relationship records. These records represent relationships with other nodes, which eliminates the (time-consuming) search-match operation found in relational databases.
Examples of Graph Databases:
- Neo4j – Free, open-source
- JanusGraph – Free, open-source
Graph databases are great for establishing data relationships especially when dealing with large data sets. They offer blazing fast query performance that relational databases cannot compete with, especially as data grows much deeper.
- Walmart uses Neo4j to provide customers personalized, relevant product recommendations and promotions
- Medium uses Neo4j to build their social graph to enhance content personalization
- Cisco uses Neo4j to mine customer support cases to anticipate bugs
Multi-Model
It’s clear that the four previous NoSQL database types have their respective advantages, which is why the multi-model database has emerged as another popular option in recent years. As its name suggests, a multi-model database combines the capabilities of wide-column, graph, document, and key-value databases. More supported data models within one database means more versatility for you – the end user – in the way you store your data.
Examples of Multi-Model Databases:
- Microsoft Azure Cosmos DB – Pricing starts at $0.25/GB, free Emulator available
- OrientDB – Free, open source
Use Cases
- RTE’s Investigations Unit uses OrientDB to establish data connections across various sources for investigative purposes
- Azure CosmosDB supports Citrix’s Identity Platform, which enables single-sign on for more than 400,000 organizations and 100 million individuals worldwide
- ASOS uses Azure Cosmos DB to deliver real-time product recommendations and instant order updates for 15.4 million customers
mongoDB: advantages and disadvantages
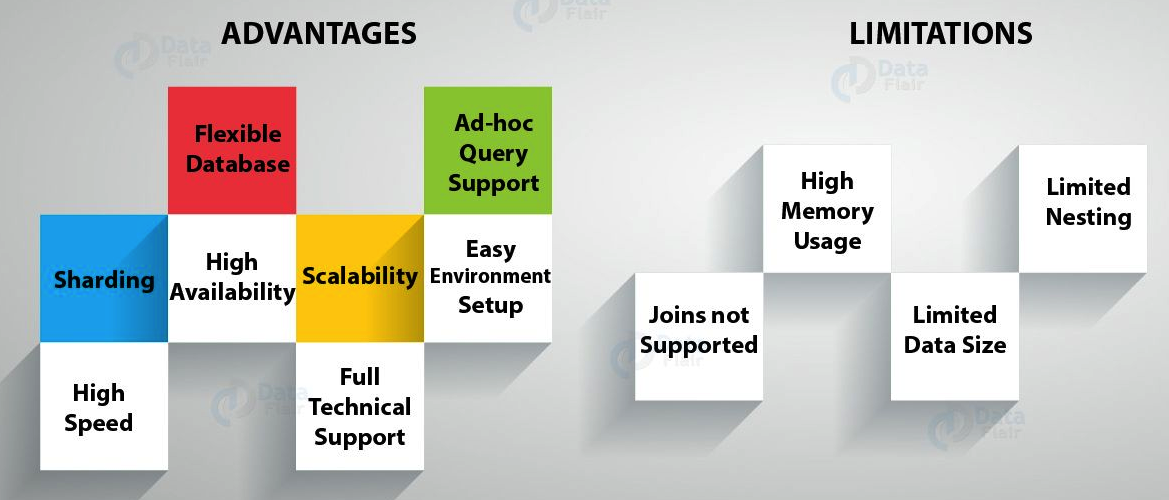
Advantages
- Flexible Database We know that MongoDB is a schema-less database. That means we can have any type of data in a separate document. This thing gives us flexibility and a freedom to store data of different types.
- Sharding We can store a large data by distributing it to several servers connected to the application. If a server cannot handle such a big data then there will be no failure condition. The term we can use here is “auto-sharding”.
- High Speed MongoDB is a document-oriented database. It is easy to access documents by indexing. Hence, it provides fast query response. The speed of MongoDB is 100 times faster than the relational database.
- High Availability MongoDB has features like replication and gridFS. These features help to increase data availability in MongoDB. Hence the performance is very high.
- Scalability A great advantage of MongoDB is that it is a horizontally scalable database. When you have to handle a large data, you can distribute it to several machines
- Ad-hoc Query Support MongoDB has a very advanced feature for ad hoc queries. This is why we don’t need to worry about fore coming queries coming in the future.
- Easy Environment Setup It is easier to setup MongoDB then RDBMS. It also provides JavaScript client for queries.
Disadvantages
- Joins not Supported MongoDB doesn’t support joins like a relational database. Yet one can use joins functionality by adding by coding it manually. But it may slow execution and affect performance.
- High Memory Usage MongoDB stores key names for each value pairs. Also, due to no functionality of joins, there is data redundancy. This results in increasing unnecessary usage of memory.
- Limited Data Size You can have document size, not more than 16MB.
- Limited Nesting You cannot perform nesting of documents for more than 100 levels.
Phylosofy of key-value storages
A Key-valuestore is very closely related to a document store—it allows the storage of a value against a key. Similar to a document store, there is no need for a schema to be enforced on the value. However, there a are few constraints that are enforced by a key-value store:
- Unlike a document store that can create a key when a new document is inserted, a key-value store requires the key to be specified
- Unlike a document store where the value can be indexed and queried, for a key-value store, the value is opaque and as such, the key must be known to retrieve the value
The most prominent use of working with a key-value store is for in-memory distributed or otherwise cache. However, implementations do exist to provide persistent storage.
A few of the popular key value stores are:
- Redis (in-memory, with dump or command-log persistence)
- Memcached (in-memory)
- MemcacheDB (built on Memcached)
- Berkley DB
- Voldemort (open source implementation of Amazon Dynamo)
Key-value stores are optimized for querying against keys. As such, they serve great in-memory caches. Memcached and Redis support expiry for the keys—sliding or absolute—after which the entry is evicted from the store. At times, one can generate the keys smartly—say, bucketed UUID—and can query against ranges of keys. For example, Redis allows retrieving a list of all the keys matching a glob-style pattern.
Though the key-value stores cannot query on the values, they can still understand the type of value. Stores like Redis support different value types—strings, hashes, lists, sets, and sorted sets. Based on the value types, advanced functionalities can be provided. Some of them include atomic increment, setting/updating multiple fields of a hash (equivalent of partially updating the document), and intersection, union, and difference while working with sets.
Set or update value against a key (Redis):
SET company "My Company" //String
HSET alice firstName "Alice" //Hash – set field value
HSET alice lastName "Matthews" //Hash – set field value
LPUSH "alice:sales" "10" "20" //List create/append
LSET "alice:sales" "0" "4" //List update
SADD "alice:friends" "f1" "f2" //Set – create/update
SADD "bob:friends" "f2" "f1" //Set – create/update