Competent
Understanding RDBMS architecture
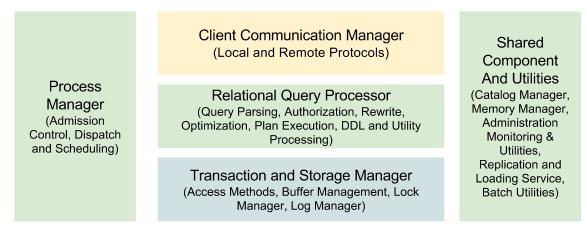
There are five major components that are exercised in a typical interaction with an RDMBS:
- Client Communication Manager – In order to communicate with a database an application needs to make a connection with a database over a network. An application establishes a connection with the Client Communication Manager. This component enables communication between various database clients through both local and remote protocols. Its main responsibility is to remember communication state, return data and control messages ( result codes, errors) as well as forward the client’s request to other parts of the DBMS.
- Process Manager – The process manager is responsible for providing a “thread of computation” for each database request from a database client. It links the threads data and control output to the appropriate communication manager client. The first decision to be made by the process manager is to determine if enough system resources are available to execute the query or defer the same until a later time.
- Relational Query Processor – On receiving a request to process a query the Relation Query Processor first checks if the user is authorised to run the query. It then compiles the query into an interim query plan which is further optimised. The resulting plan is executed by the “plan executor” which eventually makes use of the transaction and storage monitor.
- Transaction and Storage Manager – Once a query is parsed it retrieves the requested data from the Transaction and Storage Manager. It the gatekeeper to all data access and manipulation calls. The transactional and storage manager also make sure that ACID properties of a transaction are adhered too and thus the need for a lock and log manager.
- Shared Components and Utilities – There are a number of shared components and utilities that are essential for a database to run.
Transactions: ACID
It is an action or sequence of actions passed out by a single user and/or application program that reads or updates the contents of the database. A transaction is a logical piece of work of any database which may be a complete program, a fraction of a program, or a single command (like the: SQL command INSERT or UPDATE) that may involve any number of processes on the database. From the database point of view, the implementation of an application program can be considered as one or more transactions with non-database processing working in between.
TIP
A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
A transaction is a very small unit of a program and it may contain several lowlevel tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
Atomicity − this property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
Consistency − the database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
Durability − the database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
Isolation − in a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
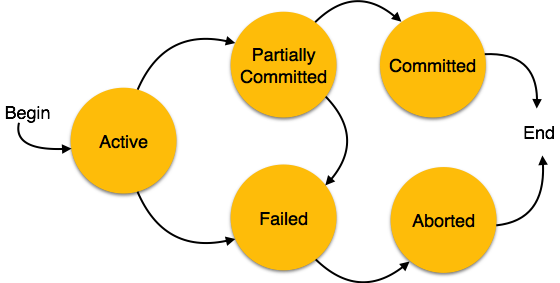
Transactions: Recovery
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
A transaction has to abort when it fails to execute or when it reaches a point from where it can’t go any further. This is called transaction failure where only a few transactions or processes are hurt.
- Logical errors − Where a transaction cannot complete because it has some code error or any internal error condition.
- System errors − Where the database system itself terminates an active transaction because the DBMS is not able to execute it, or it has to stop because of some system condition. For example, in case of deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, it may have several transactions being executed and various files opened for them to modify the data items. Transactions are made of various operations, which are atomic in nature. But according to ACID properties of DBMS, atomicity of transactions as a whole must be maintained, that is, either all the operations are executed or none.
When a DBMS recovers from a crash, it should maintain the following:
- It should check the states of all the transactions, which were being executed.
- A transaction may be in the middle of some operation; the DBMS must ensure the atomicity of the transaction in this case.
- It should check whether the transaction can be completed now or it needs to be rolled back.
- No transactions would be allowed to leave the DBMS in an inconsistent state.
There are two types of techniques, which can help a DBMS in recovering as well as maintaining the atomicity of a transaction:
- Maintaining the logs of each transaction, and writing them onto some stable storage before actually modifying the database.
- Maintaining shadow paging, where the changes are done on a volatile memory, and later, the actual database is updated.
Log-based Recovery
Log is a sequence of records, which maintains the records of actions performed by a transaction. It is important that the logs are written prior to the actual modification and stored on a stable storage media, which is failsafe.
Log-based recovery works as follows:
- The log file is kept on a stable storage media.
- When a transaction enters the system and starts execution, it writes a log about it.
Transactions: Locking
Locking protocols are used in database management systems as a means of concurrency control. Multiple transactions may request a lock on a data item simultaneously. Hence, we require a mechanism to manage the locking requests made by transactions. Such a mechanism is called as Lock Manager. It relies on the process of message passing where transactions and lock manager exchange messages to handle the locking and unlocking of data items.
Concurrency control is the procedure in DBMS for managing simultaneous operations without conflicting with each another. Concurrent access is quite easy if all users are just reading data. There is no way they can interfere with one another. Though for any practical database, would have a mix of reading and WRITE operations and hence the concurrency is a challenge.
Concurrency control is used to address such conflicts which mostly occur with a multi-user system. It helps you to make sure that database transactions are performed concurrently without violating the data integrity of respective databases.
Therefore, concurrency control is a most important element for the proper functioning of a system where two or multiple database transactions that require access to the same data, are executed simultaneously.
Concurrency Control Protocols
Different concurrency control protocols offer different benefits between the amount of concurrency they allow and the amount of overhead that they impose.
Lock-Based Protocols A lock is a data variable which is associated with a data item. This lock signifies that operations that can be performed on the data item. Locks help synchronize access to the database items by concurrent transactions.
All lock requests are made to the concurrency-control manager. Transactions proceed only once the lock request is granted.
Binary Locks: A Binary lock on a data item can either locked or unlocked states.
Shared/exclusive: This type of locking mechanism separates the locks based on their uses. If a lock is acquired on a data item to perform a write operation, it is called an exclusive lock.
- Shared Lock (S):
A shared lock is also called a Read-only lock. With the shared lock, the data item can be shared between transactions. This is because you will never have permission to update data on the data item.
For example, consider a case where two transactions are reading the account balance of a person. The database will let them read by placing a shared lock. However, if another transaction wants to update that account's balance, shared lock prevent it until the reading process is over.
- Exclusive Lock (X):
With the Exclusive Lock, a data item can be read as well as written. This is exclusive and can't be held concurrently on the same data item. X-lock is requested using lock-x instruction. Transactions may unlock the data item after finishing the 'write' operation.
For example, when a transaction needs to update the account balance of a person. You can allows this transaction by placing X lock on it. Therefore, when the second transaction wants to read or write, exclusive lock prevent this operation.
Two Phase Two-Phase locking protocol which is also known as a 2PL protocol. It is also called P2L. In this type of locking protocol, the transaction should acquire a lock after it releases one of its locks.
This locking protocol divides the execution phase of a transaction into three different parts.
In the first phase, when the transaction begins to execute, it requires permission for the locks it needs. The second part is where the transaction obtains all the locks. When a transaction releases its first lock, the third phase starts. In this third phase, the transaction cannot demand any new locks. Instead, it only releases the acquired locks.
Timestamp-Based Protocols The timestamp-based algorithm uses a timestamp to serialize the execution of concurrent transactions. This protocol ensures that every conflicting read and write operations are executed in timestamp order. The protocol uses the System Time or Logical Count as a Timestamp.
The older transaction is always given priority in this method. It uses system time to determine the time stamp of the transaction. This is the most commonly used concurrency protocol.
Lock-based protocols help you to manage the order between the conflicting transactions when they will execute. Timestamp-based protocols manage conflicts as soon as an operation is created.
Validation-Based Protocols
Summary
- Concurrency control is the procedure in DBMS for managing simultaneous operations without conflicting with each another.
- Lost Updates, dirty read, Non-Repeatable Read, and Incorrect Summary Issue are problems faced due to lack of concurrency control.
- Lock-Based, Two-Phase, Timestamp-Based, Validation-Based are types of Concurrency handling protocols
- The lock could be Shared (S) or Exclusive (X)
- Two-Phase locking protocol which is also known as a 2PL protocol needs transaction should acquire a lock after it releases one of its locks. It has 2 phases growing and shrinking.
- The timestamp-based algorithm uses a timestamp to serialize the execution of concurrent transactions. The protocol uses the System Time or Logical Count as a Timestamp.
Transactions: Isolation
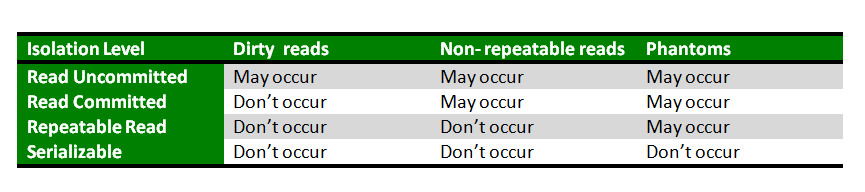
Isolation determines how transaction integrity is visible to other users and systems. It means that a transaction should take place in a system in such a way that it is the only transaction that is accessing the resources in a database system. Isolation levels define the degree to which a transaction must be isolated from the data modifications made by any other transaction in the database system. A transaction isolation level is defined by the following phenomena:
- Dirty Read – is the situation when a transaction reads a data that has not yet been committed. For example, Let’s say transaction 1 updates a row and leaves it uncommitted, meanwhile, Transaction 2 reads the updated row. If transaction 1 rolls back the change, transaction 2 will have read data that is considered never to have existed.
- Non Repeatable read – occurs when a transaction reads same row twice, and get a different value each time. For example, suppose transaction T1 reads data. Due to concurrency, another transaction T2 updates the same data and commit, Now if transaction T1 rereads the same data, it will retrieve a different value.
- Phantom Read – occurs when two same queries are executed, but the rows retrieved by the two, are different. For example, suppose transaction T1 retrieves a set of rows that satisfy some search criteria. Now, Transaction T2 generates some new rows that match the search criteria for transaction T1. If transaction T1 re-executes the statement that reads the rows, it gets a different set of rows this time.
Based on these phenomena, The SQL standard defines four isolation levels:
- Read Uncommitted – is the lowest isolation level. In this level, one transaction may read not yet committed changes made by other transaction, thereby allowing dirty reads. In this level, transactions are not isolated from each other.
- Read Committed – guarantees that any data read is committed at the moment it is read. Thus it does not allows dirty read. The transaction holds a read or write lock on the current row, and thus prevent other transactions from reading, updating or deleting it.
- Repeatable Read – is the most restrictive isolation level. The transaction holds read locks on all rows it references and writes locks on all rows it inserts, updates, or deletes. Since other transaction cannot read, update or delete these rows, consequently it avoids non-repeatable read.
- Serializable – is the Highest isolation level. A serializable execution is guaranteed to be serializable. Serializable execution is defined to be an execution of operations in which concurrently executing transactions appears to be serially executing.
Transactions: Concurrency
It is the method of managing concurrent operations on the database without getting any obstruction with one another.
A key purpose in developing a database is to facilitate multiple users to access shared data in parallel (i.e., at the same time). Concurrent accessing of data is comparatively easy when all users are only reading data, as there is no means that they can interfere with one another. However, when multiple users are accessing the database at the same time, and at least one is updating data, there may be the case of interference which can result in data inconsistencies.
Concurrency control technique implements some protocols which can be broadly classified into two categories. These are:
- Lock-based protocol: Those database systems that are prepared with the concept of lock-based protocols employ a mechanism where any transaction cannot read or write data until it gains a suitable lock on it.
- Timestamp-based Protocol: It is the most frequently used concurrency protocol is the timestamp based protocol. This protocol uses either system time or logical counter as a timestamp.
Optimization database (performance, volume)
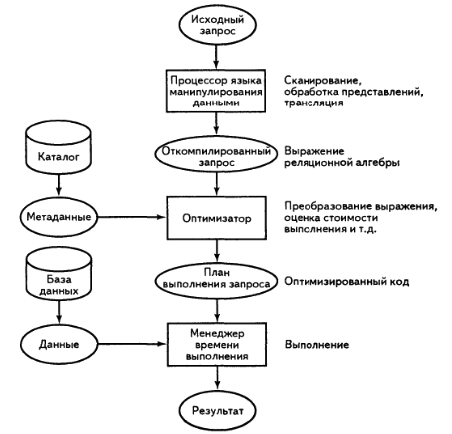
- Преобразование запроса вв внутреннюю форму
На этом этапе происходит преобразование запроса в некоторое внутреннее представление, более удобное для машинных манипуляций. Чаще всего используется та или иная модификация абстрактного синтксического дерева
- Преобразование запроса в каноническую форму
На этой стадии оптимизатор выполняет несколько операций оптимизации, которые "гарантированно являются хорошими" независимо от реальных значений данных и путей доступа к ним. Суть в том, что обычно реляционные языки позволяют сформулировать любые запросы несколькими разными способами
- Выбор потенциальнх низкоуровневых процедур
Основная стратегия состоит в том, чтобы рассматривать выражение запроса как серию низкоуровневых операций (соединения, выборки), которые в определенной степени зависят друг от друга
- Генерация различных вариантов планов вычисления запроса и выбор плана с минимальными затратами
Cоздается набор потенциальных планов запроса, после чего следует выбор лучшего (т.е. наименее дорогого)
Indexing is an effective way to tune your SQL database that is often neglected during development. In basic terms, an index is a data structure that improves the speed of data retrieval operations on a database table by providing rapid random lookups and efficient access of ordered records. This means that once you’ve created an index, you can select or sort your rows faster than before.
Indexes are also used to define a primary-key or unique index which will guarantee that no other columns have the same values. Of course, database indexing is a vast an interesting topic to which I can’t do justice with this brief description (but here’s a more detailed write-up).
This SQL optimization technique concerns the use of EXISTS(). If you want to check if a record exists, use EXISTS() instead of COUNT(). While COUNT() scans the entire table, counting up all entries matching your condition, EXISTS() will exit as soon as it sees the result it needs. This will give you better performance and clearer code.
- Index All Columns Used in 'where', 'order by', and 'group by' Clauses
- Normalize Tables
- Use Optimal Data Types
- Setting the MySQL Server Query Cache
Optimizing the Database Design by Denormalizing
Денормализация
Денормализация - намеренное приведение структуры базы данных в состояние, не соответствующее критериям нормализации, обычно проводимое с целью ускорения операций чтения из базы за счет добавления избыточных данных.
Устранение аномалий данных в соответствии с теорией реляционных баз данных требует, чтобы любая база данных была нормализована, то есть соответствовала требованиям нормальных форм. Соответствие требованиям нормализации минимизирует избыточность базы данных и обеспечивает отсутствие многих видов логических ошибок обновления и выборки данных.
Однако в некоторых случаях для некоторых запросов выборки операция соединения (JOIN) нормализованных отношений выполняется неприемлемо долго. Вследствие этого в ситуациях, когда производительность таких запросов невозможно повысить иными средствами, может проводиться денормализация - композиция нескольких отношений (таблиц) в одну, которая, как правило, находится во второй, но не в третьей нормальной форме. Новое отношение фактически является хранимым результатом операции соединения исходных отношений.
За счёт такого перепроектирования операция соединения при выборке становится ненужной и запросы выборки, которые ранее требовали соединения, работают быстрее.
Следует помнить, что денормализация всегда выполняется за счёт повышения риска нарушения целостности данных при операциях модификации.
Обычно под этим термином понимают стратегию, применимую к уже нормализованной базе данных с целью повышения ее производительности. Смысл этого действия — поместить избыточные данные туда, где они смогут принести максимальную пользу. Для этого можно использовать дополнительные поля в уже существующих таблицах, добавлять новые таблицы или даже создавать новые экземпляры существующих таблиц. Логика в том, чтобы снизить время исполнения определенных запросов через упрощение доступа к данным или через создание таблиц с результатами отчетов, построенных на основании исходных данных.
Непременное условие процесса денормализации — наличие нормализованной базы. Важно понимать различие между ситуацией, когда база данных вообще не была нормализована, и нормализованной базой, прошедшей затем денормализацию. Во втором случае — все хорошо, а вот первый говорит об ошибках в проектировании или недостатке знаний у специалистов, которые этим занимались.
Преимущества
- Повышение производительности запросов. Некоторые запросы могут использовать множество таблиц для доступа к часто запрашиваемым данным. Пример — ситуация, когда необходимо объединить до 10 таблиц для получения имени клиента и наименования товаров, которые были ему проданы. Некоторые из них, в свою очередь, могут содержать большие объемы данных. При таком раскладе разумным будет добавить напрямую поле client_id в таблицу products_sold.
- Ускорение создания отчетов. Бизнесу часто требуется выгружать определенную статистику. Создание отчетов по «живым» данным может требовать большого количества времени, да и производительность всей системы может в таком случае упасть. Например, требуется отслеживать клиентские продажи за определенный промежуток по заданной группе или по всем пользователям разом. Решающий эту задачу запрос в «боевой» базе перелопатит ее полностью, прежде чем подобный отчет будет сформирован. Нетрудно представить, насколько медленнее все будет работать, если такие отчеты будут нужны ежедневно.
- Предварительные вычисления часто запрашиваемых значений. Всегда есть потребность держать наиболее часто запрашиваемые значения наготове для регулярных расчетов, а не создавать их заново, генерируя их каждый раз в реальном времени.
Недостатки
- Место на диске. Ожидаемо, поскольку данные дублируются.
- Аномалии данных. Необходимо понимать, что с определенного момента данные могут быть изменены в нескольких местах одновременно. Соответственно, нужно корректно менять и их копии. Это же относится к отчетам и предварительно вычисляемым значениям. Решить проблему можно с помощью триггеров, транзакций и хранимых процедур для совмещения операций.
- Документация. Каждое применение денормализации следует подробно документировать. Если в будущем структура базы поменяется, то в ходе этого процесса нужно будет учесть все прошлые изменения — возможно, от них вообще можно будет к тому моменту отказаться за ненадобностью. (Пример: в клиентскую таблицу добавлен новый атрибут, что приводит к необходимости сохранения прошлых значений. Чтобы решить эту задачу, придется поменять настройки денормализации).
- Замедление других операций. Вполне возможно, что применение денормализации замедлит процессы вставки, модификации и удаления данных. Если подобные действия проводятся относительно редко, то это может быть оправдано. В этом случае мы разбиваем один медленный SELECT-запрос на серию более мелких запросов по вводу, обновлению и удалению данных. Если сложный запрос может серьезно замедлить всю систему, то замедление множества небольших операций не отразится на качестве работы приложения столь драматических образом.
- Больше кода. Пункты 2 и 3 потребуют добавления кода. В то же время они могут существенно упростить некоторые запросы. Если денормализации подвергается существующая база данных, то потребуется модифицировать эти запросы, чтобы оптимизировать работу всей системы. Также понадобится обновить существующие записи, заполнив значения добавленных атрибутов — это тоже потребует написания некоторого количества кода.
Preferred using of key-value storages
Redis – быстрое хранилище в памяти с открытым исходным кодом для структур данных «ключ-значение». Redis поставляется с набором разнообразных структур данных в памяти, что упрощает создание различных специальных приложений. Самые распространенные примеры использования Redis включают кэширование, управление сессиями, системы «издатель-подписчик» и таблицы лидеров. Это самое популярное на текущий момент хранилище пар «ключ-значение». Оно обладает лицензией BSD, написано на оптимизированном коде C и поддерживает несколько языков разработки. Название Redis является акронимом от REmote DIctionary Server. Благодаря высокой скорости и простоте Redis часто используется для мобильных и интернет-приложений, игр, рекламных платформ, «Интернета вещей», т. е. в тех случаях, когда необходима максимально возможная производительность.
Преимущества
Высочайшая производительность Все данные Redis находятся в оперативной памяти сервера, в отличие от большинства систем управления базами данных, в которых данные хранятся на жестких дисках или твердотельных накопителях (SSD). Размещаемые в памяти базы данных, такие как Redis, не требуют доступа к дисковым накопителям, что позволяет избежать потерь времени на поиск. Доступ к данным можно организовать при помощи более простых алгоритмов, в которых используется меньшее количество инструкций ЦПУ. Для выполнения типовых операций требуется менее миллисекунды.
Структуры данных в памяти Redis позволяет пользователям хранить ключи, привязанные к различным типам данных. Основной тип данных – это строка, которая может состоять из текстовых или двоичных данных размером до 512 МБ. Redis также поддерживает списки строк (List of Strings), упорядоченные в порядке вставки; множества неупорядоченных строк (Sets of unordered Strings); упорядоченные по результату множества (Sorted Sets); хеш-таблицы (Hashes), содержащие список полей и значений, и тип данных HyperLogLogs для подсчета уникальных элементов в наборе данных. С помощью Redis в памяти можно хранить практически любые типы данных.
Универсальность и простота использования Redis поставляется с несколькими инструментами, ускоряющими и облегчающими разработку и эксплуатацию, включая шаблон «издатель-подписчик», для публикации сообщений в логических каналах, доставляемых подписчикам (хорошо подходит для чатов и систем обмена сообщениями);TTL: ключи могут иметь определенное время жизни (TTL), после чего они самостоятельно уничтожаются, это используется, чтобы избежать заполнения базы данных ненужными данными; атомарные счетчики, которые обеспечивают непротиворечивость результатов в ситуации состязания; а также Lua, мощный, но несложный язык скриптов.
Репликация и сохранность В Redis применяется архитектура «ведущий–подчиненный» и поддерживается асинхронная репликация, при которой данные могут реплицироваться на несколько подчиненных серверов. Это обеспечивает как улучшенные характеристики чтения (так как запросы могут быть распределены между серверами), так и восстановление при отключении основного сервера. Для обеспечения надежности Redis поддерживает как снимки состояния на момент времени (копирование наборов данных Redis на диски), так и создание файла только для добавления (AOF) для последовательной записи на диск всех изменений данных. Любой из этих методов обеспечивает быстрое восстановление данных Redis в случае сбоя.
Поддержка удобного языка разработки Для разработчиков под Redis доступны более ста клиентов с открытым исходным кодом. Поддерживаемые языки программирования включают Java, Python, PHP, C, C++, C#, JavaScript, Node.js, Ruby, R, Go и многие другие.
Примеры использования
Кэширование Если Redis поместить «перед» другой базой данных, создается высокопроизводительный кэш в памяти, который уменьшает задержку доступа, увеличивает пропускную способность и уменьшает нагрузку на реляционную базу данных или базу данных NoSQL.
Управление сессиями Redis отлично подходит для задач управления сессиями. Можно просто использовать Redis как быстрое хранилище пар «ключ-значение» с соответствующим временем жизни (TTL) ключей сессии для управления информацией сессии. Управление сессиями обычно требуется для интернет-приложений, включая игры, сайты электронной коммерции и платформы социальных сетей.
Ограничение интенсивности Redis может измерять и при необходимости ограничивать скорость наступления событий. Используя счетчик Redis, связанный с ключом API клиента, можно подсчитать количество запросов на доступ за определенный период времени и принять меры при превышении лимитов. Ограничители интенсивности обычно используются для установки лимита по количеству публикаций на форуме, лимитирования использования ресурсов и уменьшения влияния спамеров.
Очереди Структура данных список Redis позволяет легко создавать упрощенные постоянные очереди. Списки Redis List обеспечивают выполнение элементарных операций, а также возможности блокировки, поэтому они подходят для различных приложений, в которых требуется надежный брокер сообщений или циклический список.
mongoDB: query language
Create
- insertOne(data, options)
- insertMany(data, options)
Read
- find(filter, options)
- .limit()
- .pretty()
- .count()
- .toArray()
- .forEach(passenger => printjson(passenger.name))
db.flightData.find({ distance: { $gt: 1000 } }) db.passengers.find({ "status.description": "on-time" }) - findOne(filter, options)
- find(filter, options)
Update
- updateOne(filter, data, options)
db.flightData.updateOne({ distance: 12000 }, { $set: { marker: "delete" } })- updateMany(filter, data, options)
- replaceOne(filter, data, options)
Delete
- deleteOne(filter, options)
- deleteMany(filter, options)
mongoDB: data consistency
Transaction Model & Configurable Write Availability
MongoDB is ACID compliant at the document level. One or more fields may be written in a single operation, including updates to multiple sub-documents and elements of an array. The ACID guarantees provided by MongoDB ensures complete isolation as a document is updated; any errors cause the operation to roll back and clients receive a consistent view of the document. MongoDB also allows users to specify write availability in the system using an option called the write concern. The default write concern acknowledges writes from the application, allowing the client to catch network exceptions and duplicate key errors. Developers can use MongoDB's Write Concerns to configure operations to commit to the application only after specific policies have been fulfilled - for example only after the operation has been flushed to the journal on disk. This is the same mode used by many traditional relational databases to provide durability guarantees. As a distributed system, MongoDB presents additional flexibility in enabling users to achieve their desired durability goals, such as writing to at least two replicas in one data center and one replica in a second data center. Each query can specify the appropriate write concern, ranging from unacknowledged to acknowledgement that writes have been committed to all replicas.
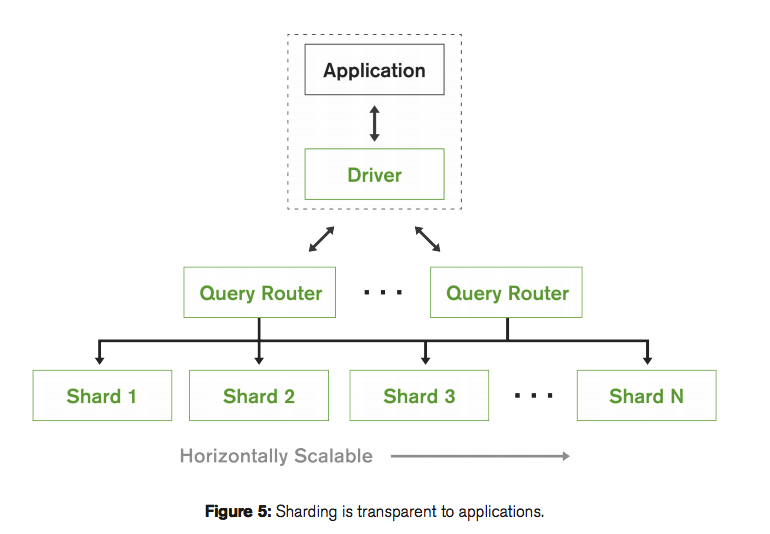
Concurrency Control
MongoDB enforces concurrency control for multiple clients accessing the database by coordinating multi-threaded access to shared data structures and objects. The granularity of concurrency control is dependent on the storage engine configured for MongoDB. WiredTiger enforces control at the document level while the MMAPv1 storage engine implements collection-level concurrency control. For many applications, WiredTiger will provide benefits in greater hardware utilization and more predictable performance by supporting simultaneous write access to multiple documents in a collection from multiple sessions. Both storage engines support an unlimited number of simultaneous readers on a document.
Journaling
MongoDB implements write-ahead journaling of operations to enable fast crash recovery and durability in the storage engine. In the case of a server crash, journal entries are recovered automatically.
The behavior of the journal is dependent on the configured storage engine:
- MMAPv1 journal commits are issued at least as often as every 100ms by default. In addition to durability, the journal also prevents corruption in the event of an unclean system shutdown. By default, journaling is enabled for MongoDB with MMAPv1. No production deployment should run without the journal configured.
- The WiredTiger journal ensures that writes are persisted to disk between checkpoints. WiredTiger uses checkpoints to flush data to disk by default every 60 seconds or after 2GB of data has been written. Thus, by default, WiredTiger can lose up to 60 seconds of writes if running without journaling – though the risk of this loss will typically be much less if using replication for durability. The WiredTiger transaction log is not necessary to keep the data files in a consistent state in the event of an unclean shutdown, and so it is safe to run without journaling enabled, though to ensure availability the “replica safe” write concern should be configured. An added feature of the WiredTiger storage engine is the ability to compress the journal on disk, reducing storage space.
For additional guarantees the administrator can configure the journaled write concern for both storage engines, whereby MongoDB acknowledges the write operation only after committing the data to the journal.
mongoDB: joins in NoSQL DBs
Some database management systems implement the join operation in their query interface, some do not. For example, Oracle, MySQL and FoundationDB implement joins, MongoDB, Oracle NoSQL and Aerospike do not. So joins are not necessarily restricted to the relational data model.
The need for joins is not a function of the data model (document-oriented in this case), but a function of the data access, aka, the number of required data relationship traversals in context of a given schema.
If not expressed as query, joins are found either in the application system logic or the interface logic, depending on the design. Most likely these are nested-loop joins or hash-based joins (less likely) or a series of selections with the application logic combining the intermediary query results into the final result data set.
And they are not joins on the complete data set either, but usually have some selection criteria. So the application system logic roughly corresponds to the optimized operator tree of a database query sub-system and in all actuality there might be many joins implemented that way throughout the application logic.
The joins are in fact implemented, just not by using a join operator on the database interface, but inside the application logic. This means that the database cannot optimize the execution, plus there are several queries coming from the application logic putting load on the database system.
And this opens up yet another trade-off: data duplication vs. application logic complexity. If the data is structured in such a way that joins are avoided (at the cost of duplication), then the application logic complexity will be reduced also (from algorithms implementing joins to algorithms issuing queries with selections/projections).
Of course, while the application logic complexity is reduced, the data management logic complexity increased as it has to manage duplicate data consistently across the database.
One of the biggest differences between SQL and NoSQL databases is JOIN. In relational databases, the SQL JOIN clause allows you to combine rows from two or more tables using a common field between them
SELECT book.title, publisher.name
FROM book
LEFT JOIN book.publisher_id ON publisher.id;
Document-oriented databases such as MongoDB are designed to store denormalized data. Ideally, there should be no relationship between collections. If the same data is required in two or more documents, it must be repeated. This can be frustrating, since there are few situations where you never need relational data. Fortunately, MongoDB 3.2 introduces a new $lookup operator which can perform a LEFT-OUTER-JOIN-like operation on two or more collections.
$lookup is only permitted in aggregation operations. Think of these as a pipeline of operators which query, filter and group a result. The output of one operator is used as the input for the next.
Aggregation is more difficult to understand than simpler find queries and will generally run slower. However, they are powerful and an invaluable option for complex search operations.
{
"_id": ObjectID("17c9812acff9ac0bba018cc1"),
"user_id": ObjectID("45b83bda421238c76f5c1969"),
"date: ISODate("2016-09-05T03:05:00.123Z"),
"text": "My life story so far",
"rating": "important"
}
We can now join data from the user collection using the new $lookup operator. It requires an object with four parameters:
- localField: the lookup field in the input document
- from: the collection to join
- foreignField: the field to lookup in the from collection
- as: the name of the output field.
{ "$lookup": {
"localField": "user_id",
"from": "user",
"foreignField": "_id",
"as": "userinfo"
} }
Therefore, our userinfo array will only ever contain one item. We can use the $unwind operator to deconstruct it into a sub-document { "$unwind": "$userinfo" }
Finally
db.post.aggregate([
{ "$match": { "rating": "important" } },
{ "$sort": { "date": -1 } },
{ "$limit": 20 },
{ "$lookup": {
"localField": "user_id",
"from": "user",
"foreignField": "_id",
"as": "userinfo"
} },
{ "$unwind": "$userinfo" },
{ "$project": {
"text": 1,
"date": 1,
"userinfo.name": 1,
"userinfo.country": 1
} }
]);
TIP
If you have relational data, use a relational (SQL) database!
mongoDB: logical splitting data between documents
Document Structure
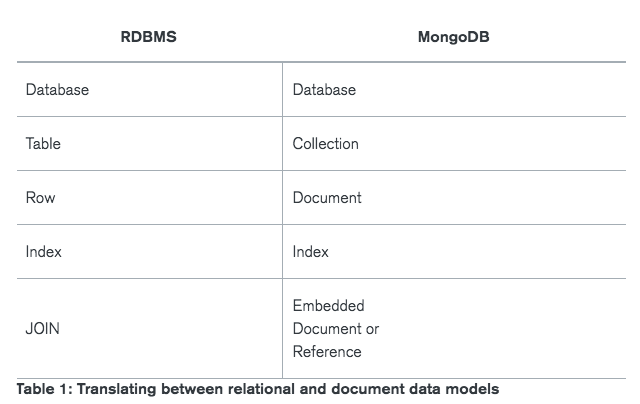
The key decision in designing data models for MongoDB applications revolves around the structure of documents and how the application represents relationships between data. MongoDB allows related data to be embedded within a single document.
Embedded Data
Embedded documents capture relationships between data by storing related data in a single document structure. MongoDB documents make it possible to embed document structures in a field or array within a document. These denormalized data models allow applications to retrieve and manipulate related data in a single database operation. For many use cases in MongoDB, the denormalized data model is optimal.

References
References store the relationships between data by including links or references from one document to another. Applications can resolve these references to access the related data. Broadly, these are normalized data models.

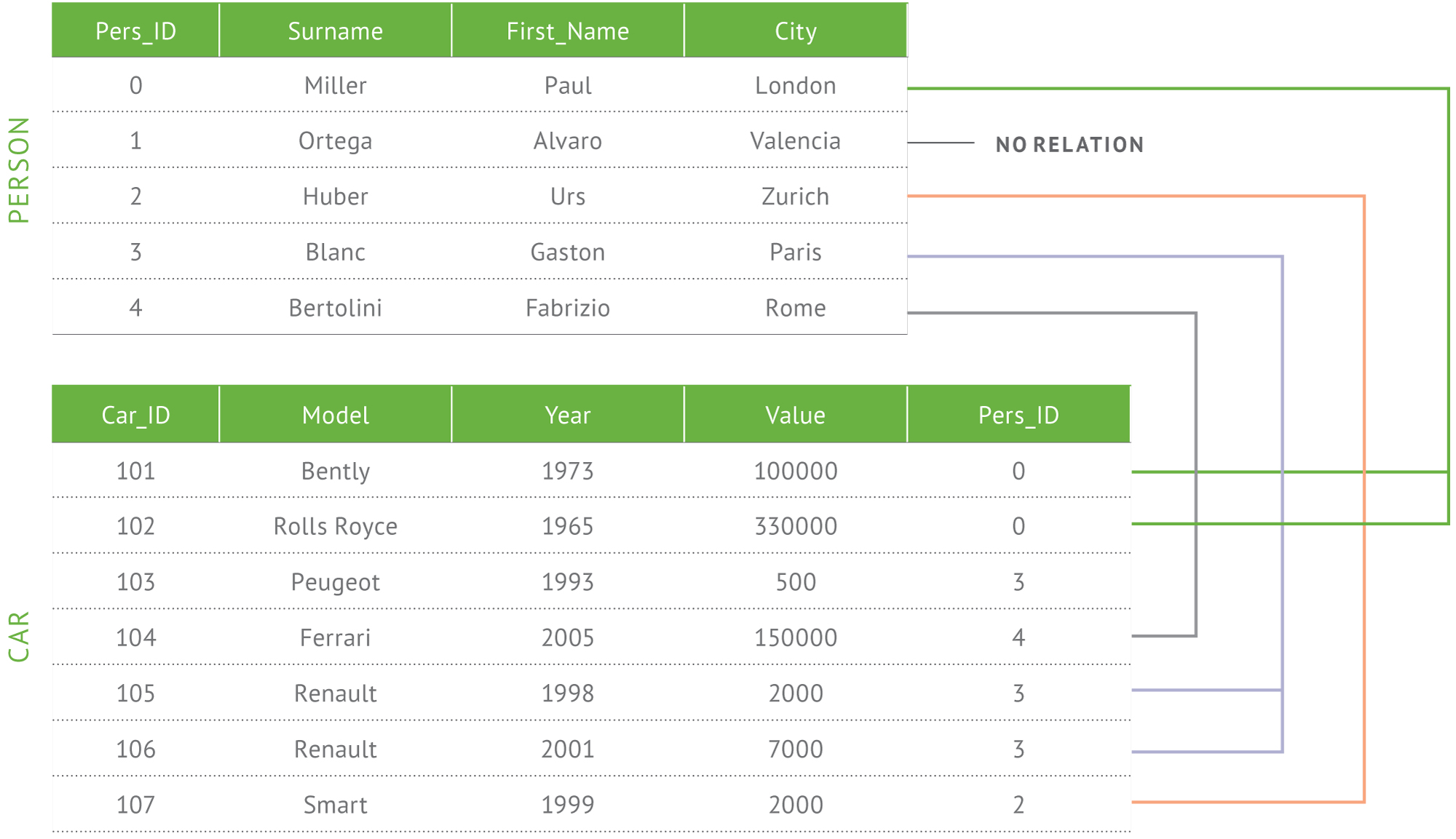
{
first_name: "Paul",
surname: "Miller",
city: "London",
location: [ 45.123, 47.232 ],
cars: [
{
model: "Bentley",
year: 1973,
value: 100000
},
{
model: "Rolls Royce",
year: 1965,
value: 330000
},
]
}